The post Psychology of Slime Molds: Regression to the Mean appeared first on Plantlet.
]]>Today we believe that being an exception is the new normal. We try our best to be an exception at something, to be an outlier. We don’t wanna be among the average people. We don’t wanna be mediocre. But mediocrity prevails in nature in every phenomenon. No matter how hard we try. If we excel at something we might be below average or close to the average at other things. If a business goes up, pretty sure it gonna be down again in near future. Nature can’t escape regression to the mean. Thus, mediocrity or average always prevails.
Regression to the Mean
In statistics, regression to the mean refers to the fact that, if a sample value is extreme(outlier), it is likely that in the near future(point) the value will be close to the mean or average. In business, if we look at the national economy, we’ll see some companies doing really good in some years. On the other hand, some companies go bankrupt. Thus, the total economy of a nation follows a regression to the mean. Again, if we note the rain rate of a decade.
Being Familiar with Slime Molds
Slime molds are charming little organisms. It has a slimy texture. Although, it had been classified as a member of the fungi kingdom in the past. Now it is not considered as a mold or fungus because it isn’t much relatable to fungus. It stays as a single cell throughout its lifetime. But, under adequate conditions, it may coalesce and form a unified collective entity called plasmodium. It looks bright yellow and big enough to be seen by the naked eye. In the wild, it mainly lives on damp leaves and rotten logs. In the laboratory it really likes oats.
Physarum polycephalum is one of many species of slime molds. You wouldn’t think there is much to say about the psychology of slime molds as they lack brain or anything that could be called similar to a nervous system. They definitely lack intelligence, thoughts or even feelings. Still a slime mold takes decisions like every living creature with a little bit of brain. In the slime mold’s limited world their decisions basically come down to
The post Psychology of Slime Molds: Regression to the Mean appeared first on Plantlet.
]]>The post Experimental Designs (Part-1): Principle and Concept appeared first on Plantlet.
]]>For any scientific studies, designing and evolving suitable methodology of an experiment in an institution or for an inquiry in the field, need very logical and systematic planning. The knowledge of how experiments come in use and in what way it is to be carried out is discussed below.
Steps for scientific processing
- Research- We need to carry out background research. Figure out what we specifically want to test or the problem that we intend to study. At the end of the research, we will be able to define the aims and objectives of the study.
- Construct a Hypothesis- After the problems and the purpose are clear and the literature on the previous work is reviewed, we have to precisely start with an assumption positive or negative.
- Test Hypothesis by doing an experiment- Prepare an overall plan or design of the investigation for studying the problem and meeting the objective. Then we carry out an experiment, which leads to either the confirmation of the hypothesis or ruling out of the hypothesis.
- Analyze the data and draw conclusions- Compile all the data and verify their accuracy and adequacy before processing further. Data can be presented graphically, through lab reports, mini-posters, or PowerPoint presentations. In a conclusion, see if the hypothesis is established as a thesis. recheck the whole plan and its execution before making logical recommendations or preparation of thesis or publication of scientific papers or reports.
- Report your results- Participate in a poster session, give a presentation at a conference, submit your findings to an established journal, or any other methods are used.
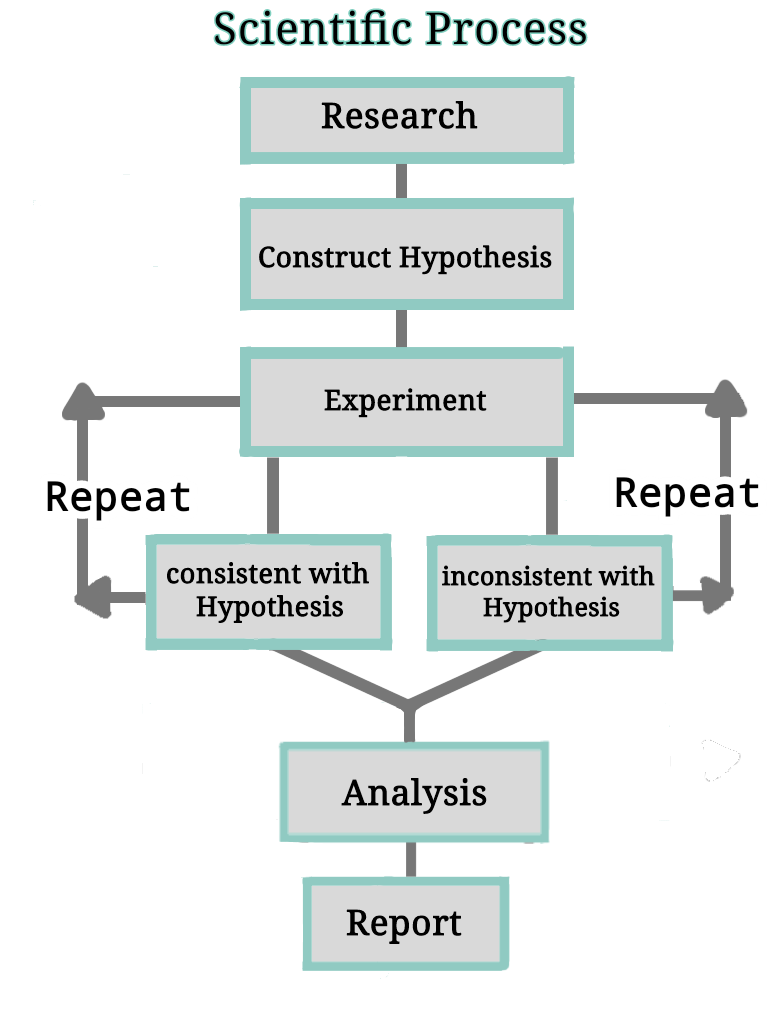
Thus it is important for any researcher to know how to carry out an experiment.
What is an experiment?
An experiment deliberately imposes a treatment on a group of objects in the interest of observing the response.
Experimental unit and Treatment
The experimental unit is the physical entity that can be assigned, at random, to a treatment. It is also the unit of statistical analysis. Adequate replications are done after which the researcher makes an inference.
Treatment is something that researchers administer to experiment units. It is also referred to as an independent variable.
Experimental design and its importance
We are concerned with the analysis of data generated from an experiment. It is wise to take time and effort to organize the experiment properly to ensure that the right type of data and enough of it is available to answer the questions of interest as clearly and efficiently as possible. This process is called experimental design.
We design an experiment to improve the precision of our answers. Thus the specific questions that the experiment is intended to answer must be clearly identified before experimenting. We should also attempt to identify known or expected sources of variability in the experimental units since one of the main aims of a designed experiment is to reduce the effect of these sources of variability on the answers to questions of interest.
Experimental Variables
Before carrying out an experiment, we should know what kinds and how many variables we are dealing with. Otherwise, the result will be less precise and may encounter an unexpected anomaly. There are three types of variables:
- Independent Variable- It is what is varied during the experiment. It is what the investigator thinks will affect the dependent variable. The investigator must choose one independent variable that is most important and appropriate under the hypothesis being tested.
- Dependent Variable– It is what will be measured. It is what the investigator thinks will be affected during the experiment. Thus it falls on the treatment group in an experiment where they are manipulated and their observations are recorded. The investigators can take as many dependent variables, necessary for experimenting.
- Control- The variable that is held constant. Since the investigator wants to study the effect of one particular independent variable, the possibility that the other factors are affecting the outcome must be eliminated. This is done by keeping all the items or subjects that we are examining identical with the exception that it does not receive the treatment or the experimental manipulation that the treatment group receives.
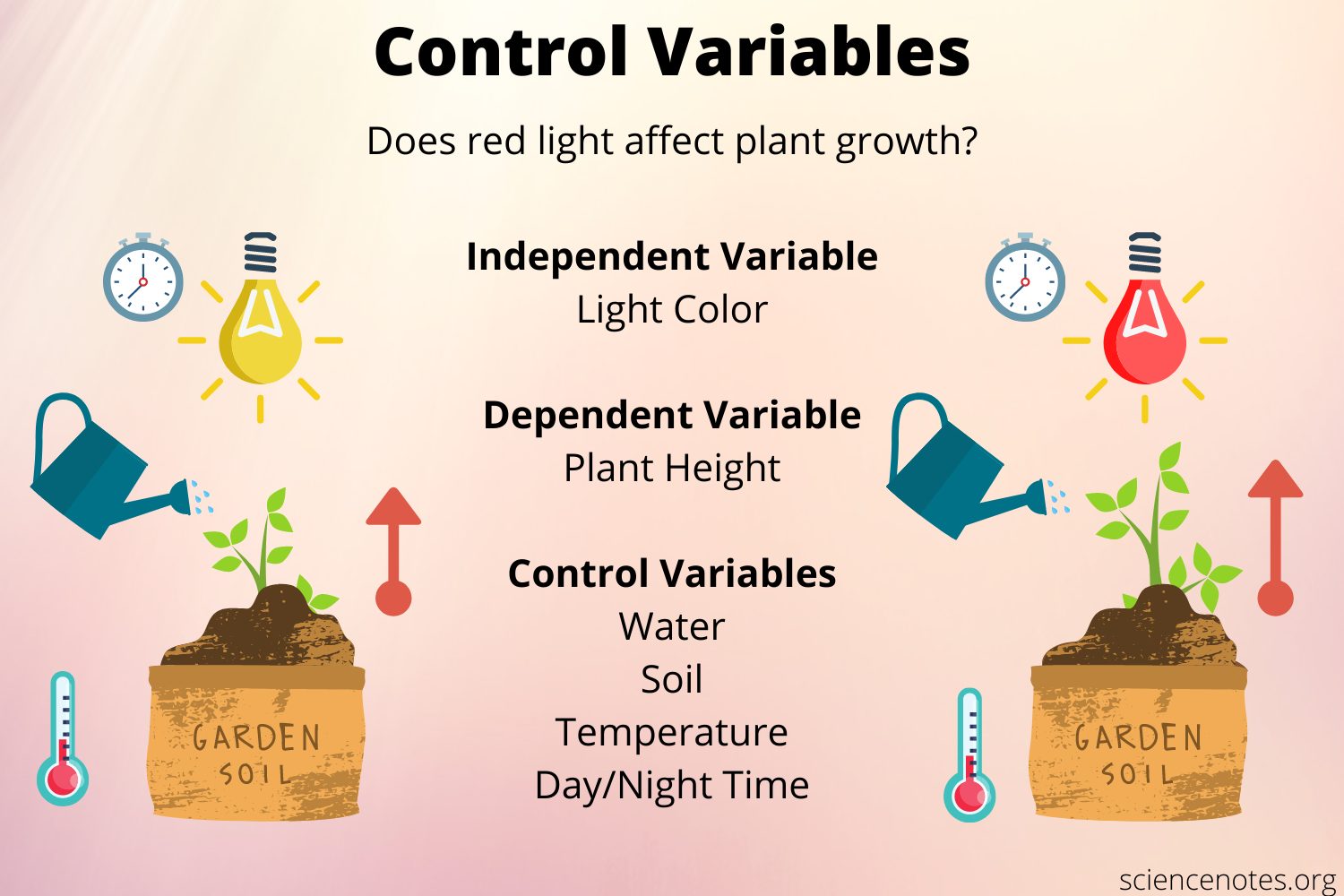
Other factors such as the nature of the study whether it is descriptive, analytical, or interventional could be identified to use the proper method of sampling and experiment. Observer and the instrumental error should also be taken into account while experimenting.
Minimizing the sources of variability
- Randomization- In an experimental group, we randomly assign objects ar individuals. Using randomization is the most reliable method of creating homogeneous treatment groups, without involving any potential biases or judgment.
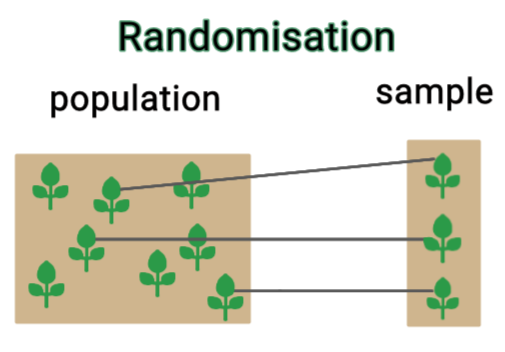
- Replication- The repetition of an experiment on a large group of subjects. If treatment is truly effective, the long term averaging effect of replication will reflect its experimental design.

Reference
- Mahajan’s Methods in Biostatistics for Medical Students and Research Workers (page-270-281)
- Notes from Biostatistics scientific methods and experiment and types of experiential design by Prof. Rakha Hari Sarker.
- “What Is a Controlled Variable? Definition and Examples” from ScienceNotes
The post Experimental Designs (Part-1): Principle and Concept appeared first on Plantlet.
]]>The post Test of Significance appeared first on Plantlet.
]]>Test of Significance
The mathematical methods by which the probability of relative frequency of an observed difference occurring by chance, is found, are called tests of significance. It may be a difference between means or proportions of sample and universe or between the estimates of experiment and control groups.
Thus, the mathematical method by which we can support or reject a claim or an inference or a hypothesis, based on collected data, is called the test of significance.
There are two basic methods of drawing the conclusion or knowing/testing the significance of the results obtained. They are-
- The estimation of a population parameter from a sample statistic.
- The testing of the hypothesis about the population parameter.
Testing of Statistical Hypothesis
‘Z test’, ‘t test’ and ‘χ² test’ are some of the common tests of significance. The stages in performing a test of significance using the method of testing a statistical hypothesis are :
- State the null hypothesis and the alternative hypothesis, e.g. Vitamins A and D make no difference in growth or alternately they play a positive or significant role in promoting growth.
- Take a random sample of individuals from the population and calculate the sample statistics.
- Convert the sample statistic to a test statistic by changing it to a standard score.
- Determine the P-value (probability of occurrence) from your collected data and estimate your null hypothesis(accept or reject the null hypothesis).
- Draw a conclusion on the basis of P-value, i.e. decide whether the difference observed is due to the chance or play of some external factors on the sample under study.
Hypothesis Testing
Hypothesis testing is a way of trying to confirm or deny a claim about a population using data from a sample.
A hypothesis test is a statistical procedure that is designed to test a claim or inference or hypothesis.
Every hypothesis test contains two hypotheses. They are :
- Null Hypothesis
- Alternative Hypothesis

Null Hypothesis
The hypothesis that always states that the population parameter or the sample statistic is equal to the claimed value is called the null hypothesis. It is denoted by H0. H0 represents a hypothesis that is believed to be true but has not been proved yet. This hypothesis nullifies the claim that the experimental result is different from or better than the one observed already. That means in the case of null hypothesis no difference between sample statistics or population parameters is observed.
For example, if the claim is that the average time to make a name-brand ready-mix pie is five minutes, the statistical shorthand notation for the null hypothesis, in this case, would be as follows: H0 : μ = 5.
Alternative Hypothesis
The hypothesis which is set up as the alternative to the null hypothesis and is used to establish a statistical hypothesis test is called the alternative hypothesis. It is denoted by Ha.
Against a null hypothesis, there could exist three possible alternative hypotheses. They are :
- The population parameter or the sample statistic is not equal to the claimed value (Ha: μ ≠ 5)
- The population parameter or the sample statistic is greater than the claimed value (Ha: μ > 5)
- The population parameter or the sample statistic is less than the claimed value (Ha: μ < 5)
Which alternative hypothesis to choose in setting up the hypothesis depends on what we are interested in concluding. The final conclusion is always given in terms of the null hypothesis. We either “reject H0 in favor of Ha ” or “do not reject H0 “. We never say “reject Ha” or even “accept Ha“. If we say “do not reject H0 ” it doesn’t mean the null hypothesis is true, rather it means we don’t have sufficient evidence against H0 in favor of Ha.
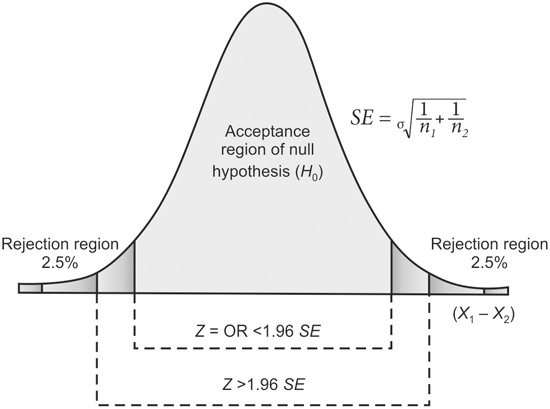
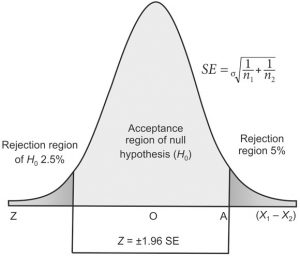
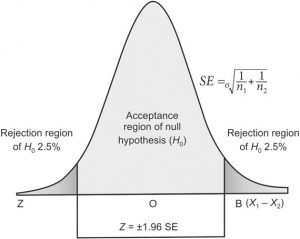
A test of significance such as Z test/ t-test/ χ2 test is performed to accept the null hypothesis H0 or to reject it and accept the alternative hypothesis Ha. To make a minimum error in rejection or acceptance of H0, we divide the sampling distribution or the area under the normal curve into two regions or zones: 1) A zone of acceptance and 2) A zone of rejection.
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
- Zone of acceptance: If the result of a sample falls in the plain area i.e. within the mean ±1.96 SE or 95% confidence interval the null hypothesis is accepted, hence this area is called the zone of acceptance for the null hypothesis.
- Zone of rejection: If the result of a sample falls in the shaded area i.e. beyond mean ±1.96 SE or 95% confidence interval it is significantly different from the estimated value. Hence, the H0 of no difference is rejected and the alternate Ha is accepted. This shaded area, therefore, is called the zone of rejection for the null hypothesis. It may be distributed at both ends or lie at one end of the area under the normal curve.
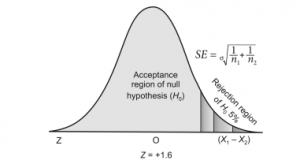
Type Ι and ΙΙ Errors
In any circumstances, the null hypothesis of no difference is rejected even when the estimate falls in the zone of acceptance at a 5% level say at point A(shown in figure 1.1). It means we are changing the
level of significance from 5% to 6, 8 or 10%, etc. This is committing a Type I error. The extent to which H0 may be rejected depends on the investigator and the circumstances such as the trial of two drugs when he may think that the difference at 10% level of significance is enough for the hypothesis to get rejected.
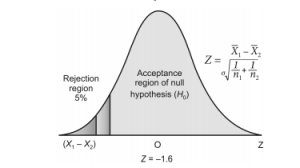
There are other situations when H0 is accepted when it should have been rejected because the estimate falls in the zone of rejection i.e. in shaded areas, say at point B (shown in figure 1.2).
Here, we are changing the level of acceptance from 5% to 4, 3, 2, or 1% level of significance. This is committing a Type II error. In such cases, we increase the size of the sample and confirm the inference.
When a statistical hypothesis is treated there are 4 ways to interpreting the result :
- The hypothesis H0 is true and our test accepts it because the result falls within the zone of acceptance at 5% level.
- The hypothesis H0 is false and our test rejects it because the estimate falls in a shaded area of rejection.
- Hypothesis H0 is true still it is rejected, though the estimate falls in the acceptance zone (Type 1 error).
- The hypothesis H0 is false but it is accepted, though the estimate falls in the zone of rejection (Type 2 error).
Reference
Mahajan BK 2002. Methods in Biostatistics
- Which of the following statements as currently written could be tested using a hypothesis test?
(A) An automobile factory claims 99% of its parts meet stated specifications
(B) An automobile factory claims that it produces the best quality cars in the country
(C) An automobile factory claims that it can assemble 500 automobiles an hour when the assembly line is fully staffed.
(D) Choices (A) and (B)
(E) Choices (A) and (C) - Which of the following scenarios as currently stated could not involve a hypothesis test without further clarification?
(A) A political party conducts a survey in an attempt to contradict published claims of the proportion of voter support for a proposed law.
(B) A commercial laboratory does sample tests on a hand sanitizer to see whether it kills the percentage of bacteria claimed by the manufacturer.
(C) A school gives its students standardized tests to measure levels of achievement compared to prior years.
(D) A laboratory takes samples of yogurt to see whether the manufacturer has met its published standard of being 99% fat-free.
(E) A university evaluation group gives random surveys to students to see whether university claims regarding the proportion of students who are satisfied with student life are valid. - You decide to test the published claim that 75% of voters in your town favor a particular school bond issue. What will your null hypothesis be?
- You decide to test the published claim that 75% of voters in your town favor a particular school bond issue. What will be your alternative bond issue?
- Given the null hypothesis Ho:µ=132, what is the correct alternative hypothesis?
- A university claims that work-study students earn an average of $10.50 per hour. What is the null hypothesis for a hypothesis test of this statement?
- The manufacturer of the new GVX Hybrid car claims that it gets an average of 52 miles per gallon of gas. What is the null hypothesis for this statement?
- Suppose that µ is the average number of songs on an MP3 player owned by a college student. Write down the description of the null hypothesis Ho:µ=228
- A think tank announces that 78% of teenagers own cell phones. What is the null hypothesis for a hypothesis test of his statement?
- A travel agency claims that people from States 1 and 2 are equally likely to have taken a vacation in Hawaii. What is the null hypothesis for this statement?
- According to a newspaper report, seven out of ten Americans think that Congress is doing a good job. What alternative hypothesis would you use if you believe this stated proportion too high?
- Amtrak claims that a train trip from New York City to Washington D.C. takes an average of 2.5 hours. What alternative hypothesis would you use if you think the average trip length is actually longer?
- An airline company claims that its flights arrive early 92% of the time. What alternative hypothesis would you use if you think this statistic is too high?
- A car manufacturer advertises that a new car averages 39 miles per gallon of gasoline. What alternative hypothesis would you use if you think this statistic is too low?
- A company claims that only 1 out of every 200 computers it sells has a mechanical malfunction. What alternative hypothesis would you use if you think this statistic is too low?
- A hospital claims that only 5% of its patients are unhappy with the care provided. What is the alternative hypothesis if you think this statistic is too low?
- a health study states that American adults consume an average of 3300 calories per day. What is the alternative hypothesis if you think this statistic is incorrect?
- A study claims that adults watch television an average of 1.8 hours per day. What is the alternative hypothesis if you think this statistic is too low?
- An investment company claims that its clients make an average of 8% return on investments every year. What alternative hypothesis would you use if you think this figure is too high?
- Someone claims that high school students living in cities with a population of more than 1 million are 25% more likely to attend college than high school students living in cities with populations less than 1 million. Write the alternative hypothesis if you think this statistic is incorrect.
The post Test of Significance appeared first on Plantlet.
]]>The post Comparison of Two Means: Student’s t-test appeared first on Plantlet.
]]>From the previous topic, we learned about test of significance, a procedure for comparing observed data with a claim or hypothesis or predicted data.
- This test of significant is used to test e claim about an unknown population and for testing the research hypothesis against the H0.
- Null hypothesis (H0) denotes that there is no difference between two population mean.
- In some statistical analysis this researchers need to compare the means of two or more variables or groups of data to easier their work .In case of two variables, comparison of mean can be measured by some specific significance test .
- Here we are going to know about such a hypothesis test called as student’s t-test.
- Comparison of means of two samples is occurred to find whether difference of two means of two groups is significant or not.
Student’s t-test
A t-test is a statistical test that is used to compare the means of two groups. It is often used in hypothesis testing to determine whether a process or treatment actually has an effect on the population of interest, or whether two groups are different from one another.
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website

Discovery of student’s t-test
- William Scaly Gusset discovered student’s t-test in 1908.
- Born – June 13,1908 (at Canterbury, Kent, England )
Died – October 16, 1927 (aged 61 at Beaconsfield, Buckinghamshire, England) - Known for student’s t-distribution.
- Test of significance of difference in means are discussed under two heads:
-
-
-
-
-
- t-test for large samples, (This test is also called Z-test)
- t-test for small samples.
-
-
-
-
- t-test for small samples are applied as
-
-
-
-
-
- Unpaired t-test (two independent samples) and
- Paired t-test (single sample correlated observations)
-
-
-
-
- Two essential conditions for these tests are
-
-
-
-
- It should be ensured that samples are selected randomly, and
- There should be homogeneity of variances in the two samples.
-
-
-
Formula of student’s t-test (and Z test)
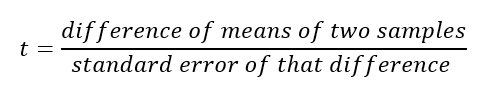
A. Estimating the difference of means of two samples
-
-
- We already know, mean is an arithmetic average of a sample or population.
-
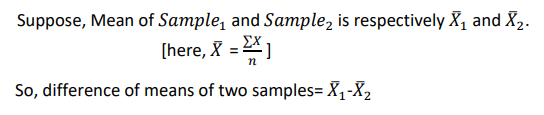
B. Estimating the Standard error of that difference
-
-
- SE (Standard error) refers to SD (standard deviation) of the distribution of sample.
- It is the approximate SD of a statistical sample population.
- In other word, In statistics, a sample mean deviates from the actual mean of a population,this deviation is the standard error of the mean.
-
Formula to estimate SE
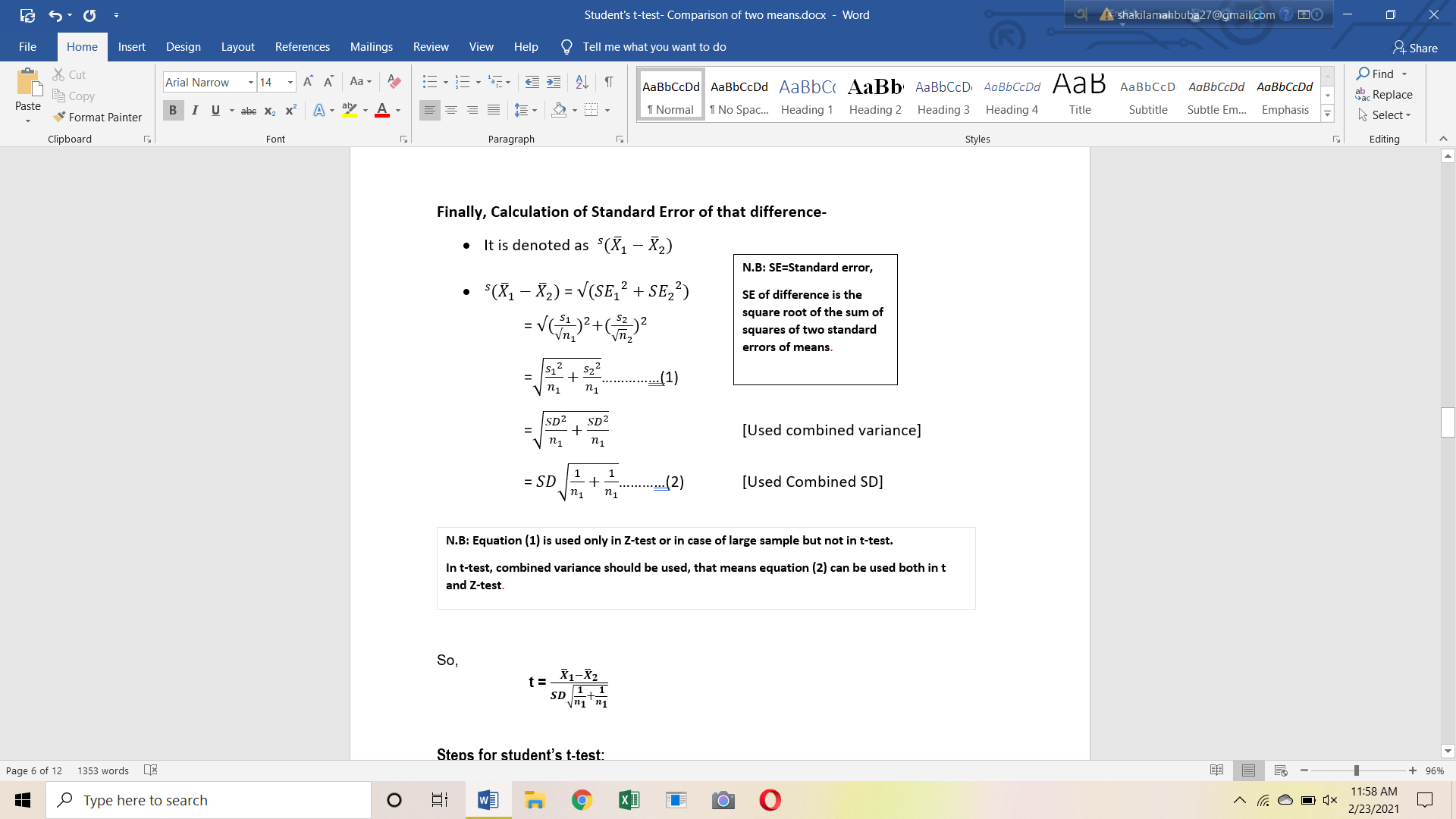
Steps for student’s t-test
Step 1: Calculate the t-value
Discussed earlier.
Step 2: Calculate the degrees of freedom

Step 3: Determine the critical value
- The critical value represents the predicted or claimed value from which difference between the two values should be considered statistically significant.
- We can find the critical value from the t distribution table below using the degrees of freedom.
N.B: If there’s no specified alpha level, we should use P0.05 (95% confidence level) and we must take the value of two tails.
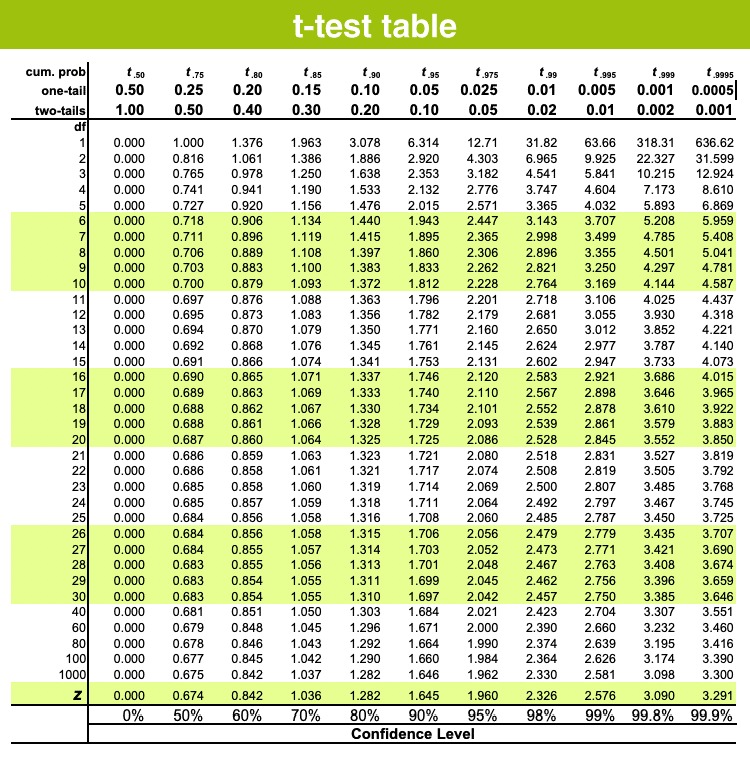
- The column header are the t distribution probabilities (alpha). The row names are the degrees of freedom (df). Student t table gives the probability that the absolute t value with a given degrees of freedom lies above the tabulated value.
Step 4: Compare the t-statistic value to critical value
- If the hypothesis value is equal or less than the critical value at the probability of 5% level, then the result is non significant, that means there have no significant different between two value.
- If non-significant, it can be claim that the null hypothesis (Ho) would be accepted.
- On the other hand, if the result value is greater than the critical value, then there exists a significant difference between them.
So, the null hypothesis would be rejected and an alternative hypothesis should be taken. In this case, the estimates falls in the area of rejection.
Application and examples of t-test
Unpaired Samples
- Two large samples t test (Generally, mean and SD value are known here):
Example
Index of data of 40 boys and 46 girls gave following values.
| Gender | Mean | SD2 |
| Boys | 53.11 | 228.57 |
| Girls | 48.63 | 395.85 |

From t table, we can find that the critical t value at 95% confidence level is 1.98 which is greater than our hypothesis value, hence the difference is probably due to chance that means not significant and also the null hypothesis is accepted.
2. Two small samples t test:
- Applied to unpaired data of independent observations made on individuals of two different or separate groups or samples.
- Use only combined variance.
Example
- In a nutritional study, 13 children were given a usual diet plus vitamins A&D tablets while the second comparable group of 12 children was taking the usual diet. After 12 months, the gain is in weight in pounds was noted as given in the table below.
Can we say that vitamins A and D were responsible for this difference?
| Group A | Group B | ||
| XA | XA2 | XB | XB2 |
| 5
3 4 3 2 6 3 2 3 6 7 5 3 |
25
9 16 9 4 36 9 4 9 36 49 25 9 |
1
3 2 4 2 1 3 4 3 2 2 3
|
1
9 4 16 4 1 9 16 9 4 4 9
|

Comments
df = 23
At 23 df the highest obtainable value of ‘t’ at 5% level of significance is 2.069 as found on reference to ‘t’ table. The ‘t’ value in this experiment is found at 2.74 which is much higher than the critical value. The significance is real and null hypothesis rejected.
Paired samples
- It is at applied to paired data of independent observations .
- When each individual give a pair of observations.
- To compare the results of two different lab techniques.
- To study the comparative accuracy of two instruments.
- To study the effect of two drugs.
- To study the role of a factor or cause when the observations are made before and after it’s application.
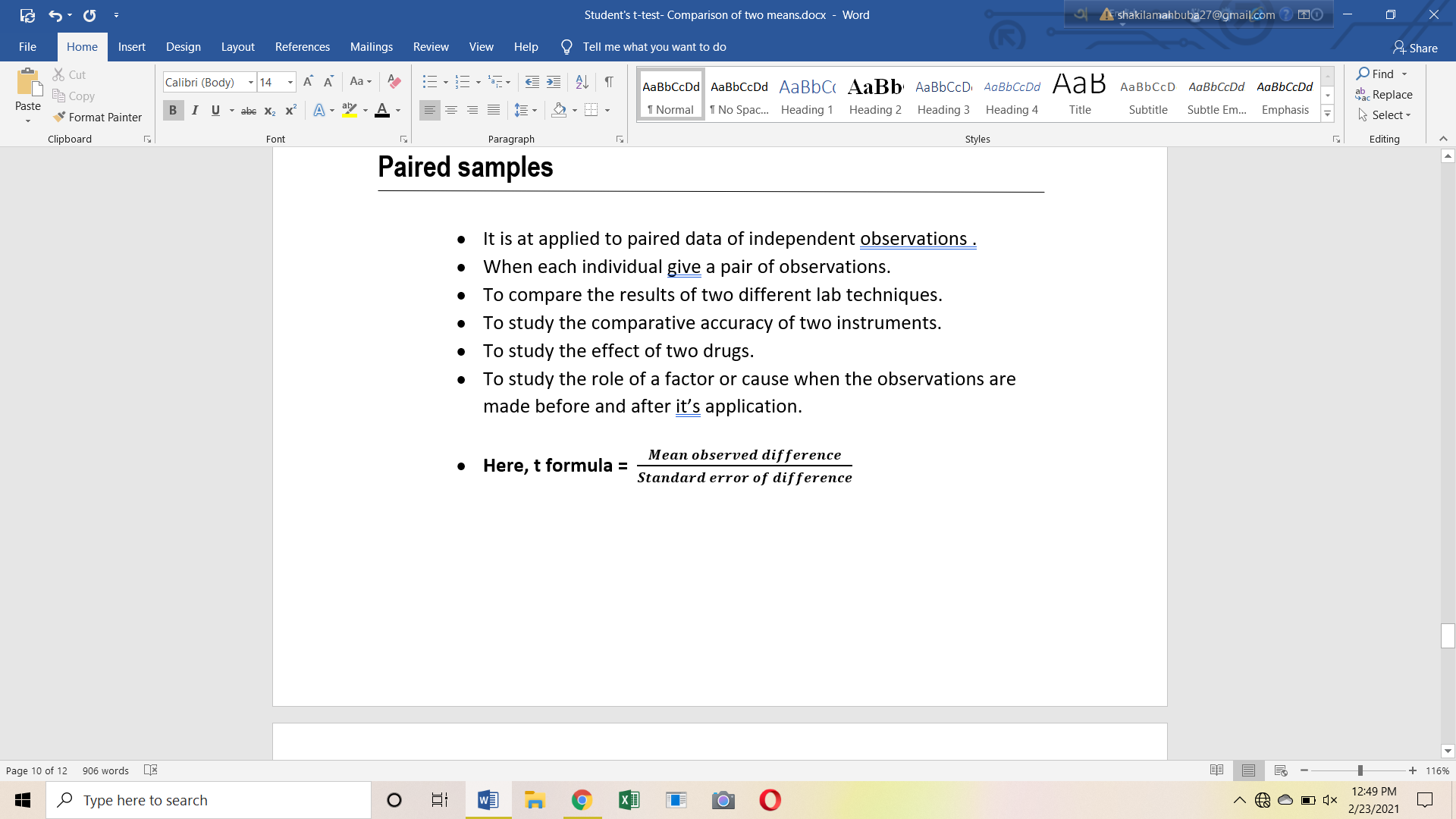
Example
Plant height in cm is given below:
| Serial no. | Height after exposed to light (cm) | Height after exposed to dark (cm) | Difference (cm) |
Differencesquare |
| X1 | X2 | x = X1 – X2 | x2 | |
| 1. | 142 | 138 | 4 | 16 |
| 2. | 140 | 136 | 4 | 16 |
| 3. | 144 | 147 | -3 | 9 |
| 4. | 144 | 139 | 5 | 25 |
| 5. | 142 | 143 | -1 | 1 |
| 6. | 146 | 141 | 5 | 25 |
| 7. | 149 | 143 | 6 | 36 |
| 8. | 150 | 145 | 5 | 25 |
| 9. | 142 | 136 | 6 | 36 |
| 10. | 148 | 146 | 2 | 4 |
| Σ x = 33 | Σ x2 = 193 |
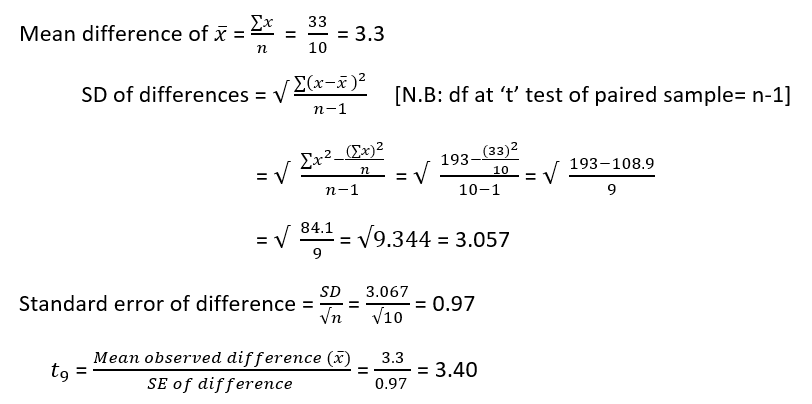
Comment
- df = 9,
- At 5% significant level, ‘t’ value is 2.26.
- Calculated value is so much higher than critical value.
- Significant difference is observed.
- Null hypothesis (Ho) is rejected.
Reference
- Lecture from student’s t-test and comparison of two means by Professor Rakha Hari Sarker.
- Book – Methods in Biostatistics for Medical Students and research workers BK Mahajan.
- Wikipedia.org
Revised by
The post Comparison of Two Means: Student’s t-test appeared first on Plantlet.
]]>The post Interrelationships of quantitative variables: Correlation and Regression appeared first on Plantlet.
]]>In the experiment, we measure the two continuous characters which are associated with each other. For example, the height of the plant and the temperature of the atmosphere. Accordingly, to understand the relationship between two such variables, we need to know how they are related and how the relationship can be expressed in a visual form.
Correlation
The statistical technique to determine the relationship or association between two quantitative variables is called correlation. In other words, it determines the relationship between two quantitative variables. However, it does not prove that one particular variable causes the change in the other.
Correlation coefficient
In correlation coefficient, we measure the degree of the relationship between two sets of figures in terms of another parameter. A simple correlation coefficient is denoted by the letter “r”. In addition, it is known as Pearson’s correlation or product-moment correlation coefficient. For population coefficient, we use the Greek letter “ρ”. Its pronunciation is “rho”. Certainly, the absolute value of r remains constant irrespective of change of origin.
The extent of correlation varies between minus one and plus one (-1 ≤ r ≤ 1). The value is in a fraction with a positive or negative sign.
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
- The sign of “r” denotes the nature of the association.
- The value of “r” denotes the strength of the association.
Type of Correlation
It is common to use a scatter diagram as a visual representation of data. We can show on a graph paper by plotting each pair of variables (X and Y). Consequently, placing a dot at the point corresponding to the values of X and Y.
Perfect Positive Correlation
- The two variables are directly proportional. In other words, fully correlate with each other.
- The correlation coefficient (r) is +1.
- Both variables rise or fall at the same proportion.
- The graph forms a straight line from the lower ends of the X and Y-axis.
- When we draw a scatter diagram, all points fall on this straight line.
Perfect Negative Correlation
- The two variables are inversely proportional to each other.
- The correlation coefficient (r) is -1.
- When one variable rises, the other variable falls at the same proportion.
- The graph will show a straight line from either of the extreme ends.
- When we draw a scatter diagram, all points fall on this straight line.
Moderately or Partially Positive Correlation
-
The two variables are moderately proportional to one another.
- The correlation coefficient (r) = 0 < r < 1.
- The variables are moderately proportional. i.e. They rise and fall in a similar proportion.
- The graph forms an imaginary line from the lower ends of both the X and Y-axis.
- When we draw a scatter diagram, the points will scatter around an imaginary mean line.
Moderately or Partially Negative Correlation
- The two variables are moderately inversely proportional to each other.
- The correlation coefficient (r) = -1< r< 0.
- The variables are moderately proportional. i.e. when one variable rises, the other variable falls at a similar proportion.
- The graph forms an imaginary line from either of the extreme ends.
- When we draw a scatter diagram, the points will scatter around an imaginary mean line.
Absolutely No Correlation
- The two variables have no association with each other.
- The correlation coefficient (r) = 0
- Both the variables rise or fall independently.
- The graph shows no imaginary line. Therefore, no trend of correlation.
- When we draw a scatter diagram, the points will be much scattered.
Calculation of Correlation coefficient
This calculation is introduced by Professor Karl Pearson. It is used to determine the direction and degree of the linear relationship between two variables. The variables must be normally distributed for this method to be applied.
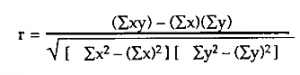
Formula:
Where numerator indicates variability between two variables.
Hypothesis testing from Pearson Correlation
As we carry out an experiment and take observations from the sample, the observed value of “r” has to be tested for significance. The following formula is for the calculation of a small sample. We set up null-hypothesis as:
Ho = There is no significant relationship between dependent and independent variables.
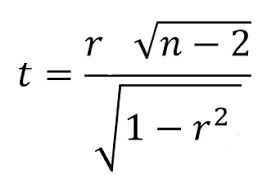
Formula:
where the degrees of freedom = n-2.
Regression
We use regression analysis to describe the relationships between a set of independent variables and the dependent variable. Regression analysis produces a regression equation. Moreover, the coefficients represent the relationship between each independent variable and the dependent variable. Therefore, it enables the user to predict the values of one variable on the basis of the other variable. For instance, on the positive or negative side, beyond the mean. Francis Galton coined the term “regression” in the nineteenth century. He described a biological phenomenon through regression.
Regression coefficient
The regression coefficient is denoted by the letter “b”. It shows the gradient or slope of the straight line of correlation. Moreover, it can calculate the equation for a straight line in correlation (Y= a+bX).
Formula: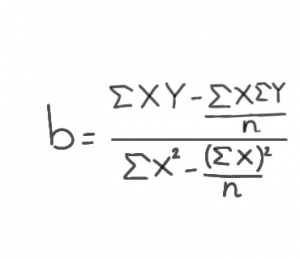
Plotting Graph
The calculated b is placed into the equation. Consequently, “a” is a constant for Y-intercept. We can find by subtracting the product of regression coefficient and mean of X from the mean of Y:
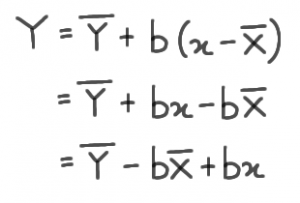
Finally, we plot a straight line. Place the value of X and Y. The lines will go through the points.
Reference:
- Mahajan’s Methods in Biostatistics for Medical Students and Research Workers- page 219-269.
- Notes from Regression analysis and correlation by Prof. Rakha Hari Sarker.
- pictures from here
The post Interrelationships of quantitative variables: Correlation and Regression appeared first on Plantlet.
]]>The post Analysis of Variance and F test appeared first on Plantlet.
]]>We can test the significance of the two sample means by using a t-test. However, in cases where there are more than two samples, it is done by Analysis of Variance (ANOVA). This method is carried out by comparing sample variances using Variance Ratio Test or F test. So at first, let’s learn about the F test which is discussed below:
Variance Ratio Test (F test)
The variance ratio test was first conducted and named after a British statistician called Ronald Aylmer Fisher (17 February 1890 – 29 July 1962). It is any statistical test in which the test statistic has an F-distribution under the null hypothesis. It is most often used when comparing statistical models that have been fitted to a data set, in order to identify the model that best fits the population from which the data were sampled. The value of F is equal to the ratio of variance.
F= Estimate variance between groups ( including treatment effects)/ Estimate variance within groups (excluding treatment effects)
In ANOVA the F test is determined as the final goal that indicates the presence or absence of a significant difference between more than two samples. In the context of ANOVA, the sample variances are called mean squares, or MS values.
Analysis of Variance (ANOVA)
General logic and basic formulas for the hypothesis testing procedure known as analysis of variance (ANOVA). The purpose of ANOVA is much the same as the t-tests. The goal is to determine whether the mean differences that are obtained for sample data are sufficiently large to justify the conclusion that there are meaningful differences between the populations from which the samples were obtained.
There are two methods of ANOVA depending on the condition of samples in which they are grouped.
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
One-way classification of Variance
If the analysis concerns with testing the difference between two sets of groups without any further categorization according to the other factors concerned, we use one-way ANOVA test. Steps of finding F value in ANOVA is given with examples-
Example- The table is given where it shows a record of the number of new leaves observed under different concentrations of hormone given.
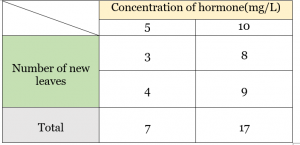
Step1: Write null hypothesis. For example here, it can be stated as “there is no significant difference/ variation among the treatments (different concentration of hormones)”
Step2: Calculate sum of square (Total SS) using the formula- ∑x2 − (∑x) 2 ⁄ n [where (∑x) 2 ⁄ n is the correction factor and “n” is the number of observed samples]
here, Total SS = (32+ 4 2+ 82 +92)− (7+17)2/4
= 170− 144
= 26.
Step3: Calculate Treatment Sum of square using formula- (total of 1st treatment)2/n + …..+(total of last treatment)2/n − (∑x) 2 ⁄ n [where n is the number of observation under one treatment]
here, Treatment SS = (72/2 + 172/2) − (7+17) 2 ⁄ 4
= 169 − 144
= 25.
Step4: Calculate Residual Sum of square using formula – Residual SS= Total SS− Treatment SS
here, Residual SS= 26 − 25 = 1
Step5 : Calculate degrees of freedom (df) for total, treatment, and residual. For total and treatment, it is n−1 and for residual, it is total degrees of freedom− treatment degrees of freedom.
here, treatment df= 2−1 = 1 and
residual df= (4−1) − (2−1)= 2
Step6: Calculate mean square for treatment and residual using formula- Mean square = Sum of square/degrees of freedom.
here, Treatment mean square = 25/1 = 25
and Residual mean square = 1/2 = 0.5
Step7: Calculate variance ratio or F value using the formula – Mean square of treatment/ Mean square of Residual.
Step8: Draw ANOVA table including all the headlines below-

Step9: Compare the calculated F value with that of the F distribution table and comment. If the calculated value is greater than the tabulated value, the null hypothesis is rejected. Thus there is a significant difference in the treatment. If it’s small, vise versa.
Two-way classification of variance
If the analysis is concerns with testing the difference between two sets of groups with further categorization according to two or more factors concerned we use two way ANOVA test. The steps for finding F value in 2 way ANOVA is quite different as in the one way as we have to calculate the treatment sum of square values for treatment and factors separately. So there will be more than one treatment value.
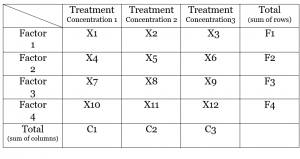
A simplified table is given as an example-
Step1 and 2 are the same as in one-way ANOVA.
Step3: Calculate Treatment Sum of square for both treatments applied and factors using formula- (total of 1st treatment)2/n + …..+(total of last treatment)2/n − (∑x) 2 ⁄ n.
here, Treatment sum of square for treatments (concentration) = (C1)2/n + (C2)2/n + (C3)2/n − (∑x) 2 ⁄ n
and Treatment sum of square for factors = (F1)2/n + (F2)2/n + (F3)2/n + (F4)2/n − (∑x) 2 ⁄ n
Step4: Calculate Residual Sum of square using formula- Residual SS = Total SS − (Treatment SS + Factor SS)
Step5: Calculate degrees of freedom for Total, Treatment, Factor, and Residual as same way done in one way ANOVA
Step6: Calculate Mean square for 2 Treatment Sum of squares for different treatments (concentration) and factor and for residual Sum of squares, using formula- Mean square = Sum of square/degrees of freedom.
Step 7: Calculate variance ratio or F value for both Mean square values.
here, F value for treatments (concentration)= mean square of treatment (concentration)/ mean square of residual
and F value for factors= mean square of factors/ mean square of residual
Step8: Draw ANOVA table including all the headlines below-
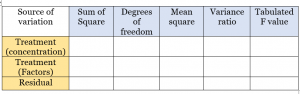
Step9: Compare the calculated F value with that of the F distribution table and comment. If the calculated value is greater than the tabulated value, the null hypothesis is rejected. Thus there is a significant difference in the treatment. If it’s small, vise versa.
F distribution table is given below. We will record the intercept value of horizontal (degrees of freedom for treatment) and vertical (degrees of freedom for residual) as tabulated F value.
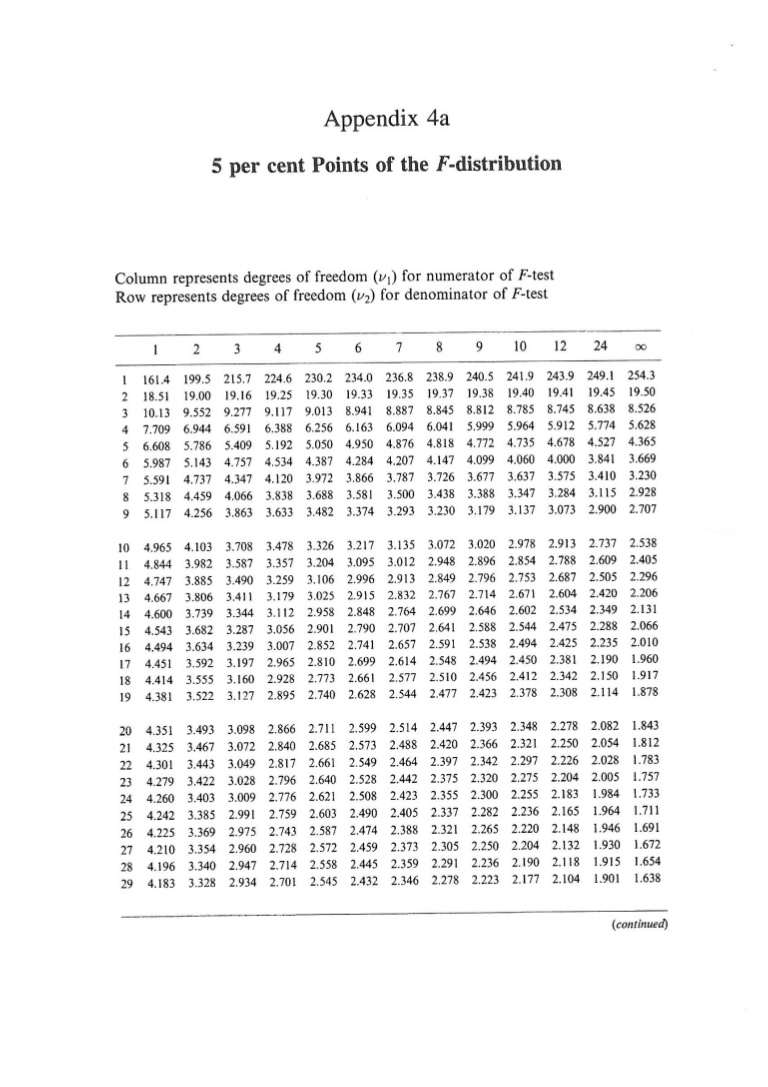
Reference
- slides from One way ANOVA, Two way ANOVA, F test by Prof. Rakha Hari Sarker.
- Mahajan’s Methods in Biostatistics for medical students and research workers 9th edition (page-212-217)
The post Analysis of Variance and F test appeared first on Plantlet.
]]>The post Measures of Dispersion appeared first on Plantlet.
]]>Range
The range consists of a bunch of data that shows the distinction between the highest and lowest values among the data set. So as to seek out the range, it’s necessary to first order the data from lowest to highest. Then we have to subtract the smallest value from the largest value in the set.
Mean deviation
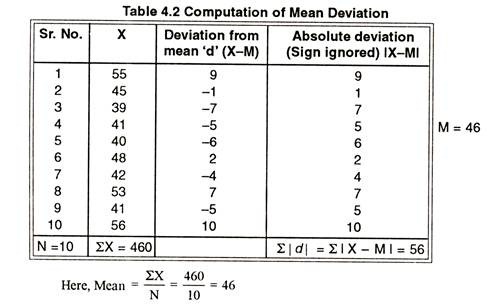
Mean deviation is a statistical measure of the average deviation of values from the mean within a set of samples. It’s calculated by finding the average of the observations. Then the difference of each observation from the mean is decided. The deviations then has got to be averaged. This analysis is mostly used to calculate how sporadic observations are from the mean.
2 5 7 10 12 14
Find out the average of these values by adding them and then and dividing them by the amount of values. In our example, the average is 8.3 (2+5+7+10+12+14=50, which is divided by 6).
Find the difference between each value and the average. Using our example, the differences are: 2 – 8.3 = 6.3 5 – 8.3 = 3.3 7 – 8.3 = 1.3 10 – 8.3 = 1.7 12 – 8.3 = 3.7 14 – 8.3 = 5.7
Find out the average of the differences by adding them and dividing by the number of observations. The average of the differences in this example is 3.66: (6.3+3.3+1.3+1.7+3.7+5.7 divided by 6).Get Free Netflix Now
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
Variance
Variance is actually the expectation of the squared deviation of a variate from its mean. Informally, variance measures how far a group of numbers are spread out from their average value.
The variance is actually the square of the standard deviation.

*Variance value is usually positive[0 to (+ve)]
Standard Deviation(SD)
In statistics, the standard deviation is a calculation of the amount of variation or dispersion of a group of values. A low standard deviation directs that the values tend to be close to the mean of the set, on the other hand a high standard deviation indicates that the values are spread out over a wider range.


Standard Error(SE)
Whatever be the sampling procedure or the care taken while selecting the sample, the sample estimates of statistics, (X —, s or p) will differ from population parameters (μ, σ or P) because of chance or biological variability. Such a difference between sample and population values is measured by statistic know as sampling error or standard error or (SE).
**Standard error is thus a measure of chance variation and it doesn’t mean error or mistake.

The standard error is the measure of the approximate standard deviation of a statistical sample . The standard error measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population and this deviation is named the standard error of the mean.
The term “standard error” refers to the standard deviation of various sample statistics, such as the mean or median. For instance, the term “standard error of the mean” refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample are going to be.
The relationship between the standard error and the standard deviation therefore is , for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is reciprocally proportional to the sample size. The greater the sample size, the smaller the standard error because the statistic will approach the actual value.
- The standard error is the measure which shows the approximate standard deviation of a statistical sample.
- The standard error will consist the variation between the calculated mean of the population and one which is taken into account, or accepted as accurate.
- The more data points involved within the calculations of the mean, the smaller the standard error.
Coefficient of Variation
The coefficient of variation is a statistical measure which shows the dispersion of data points within a data series around the mean. The coefficient of variation represents the ratio of the standard deviation to the mean and it is a useful statistic for comparing the degree of variation from one data series to a different one.


Confidence Interval
A confidence interval refers to the probability that a population parameter will fall between two set values for a certain proportion of times. Confidence intervals measure the degree of uncertainty or certainty in a sampling method and can take any number of probabilities with the foremost common being a 95% or 99% confidence level.
- A confidence interval calculates the likelihood or probability that a population parameter will fall between two set values.
- Confidence intervals calculate the degree of uncertainty or certainty in a sampling method.
- Most of the time, confidence intervals reflect confidence levels of 95% or 99%.
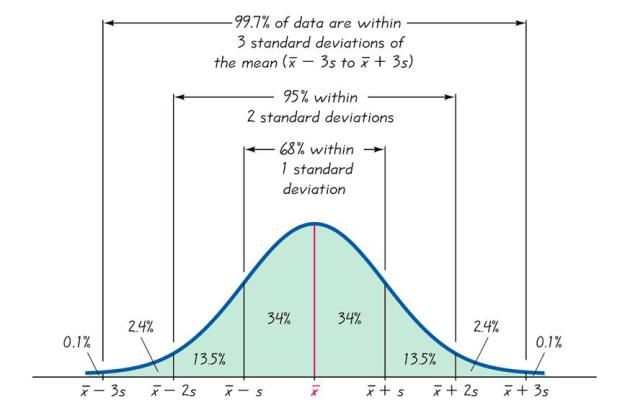
Empirical Rule
The empirical rule conjointly named as the three-sigma rule or the 68-95-99.7 rule provides a quick estimate of the spread of data in a normal distribution given the mean and standard deviation. Specifically the empirical rule indicates that for a normal distribution:
- 68% of the info/data will fall within one standard deviation of the mean.
- 95% of the info/data will fall within two standard deviations of the mean.
- Almost all (99.7%) of the info or data will fall within three standard deviations of the mean.
Q&A
1. What does the standard deviation measure?
2. According to the 68-95-99.7 rule, or the empirical rule, if a data set has a normal distribution, approximately what percentage of data will be within one standard deviation of the mean?
3. A realtor tells you that the average cost of houses in a town is $176,000. You want to know how much the prices of the houses may vary from this average. What measurement do you need?
(A) standard deviation
(B) interquartile range
(C) variance
(D) percentile
(E) Choice (A) or (C)
4. What measure(s) of variation is/are sensitive to outliers?
(A) margin of error
(B) interquartile range
(C) standard deviation
(D) Choices (A) and (B)
(E) Choices (A) and (C)
5. You take a random sample of ten car owners and ask them, “To the nearest year, how old is your current car?” Their responses are as follows: 0 years, 1 year, 2 years, 4 years, 8 years, 3 years, 10 years, 17 years, 2 years, 7 years. To the nearest year, what is the standard deviation of this sample?
6. A sample is taken of the ages in years of 12 people who attend a movie. The results are as follows: 12 years, 10 years, 16 years, 22 years, 24 years, 18 years, 30 years, 32 years, 19 years, 20 years, 35 years, 26 years. To the nearest year, what is the standard deviation for this sample?
7. A large math class takes a midterm exam worth a total of 100 points. Following is a random sample of 20 students’ scores from the class:
Score of 98 points: 2 students
Score of 95 points: 1 student
Score of 92 points: 3 students
Score of 88 points: 4 students
Score of 87 points: 2 students
Score of 85 points: 2 students
Score of 81 points: 1 student
Score of 78 points: 2 students
Score of 73 points: 1 student
Score of 72 points: 1 student
Score of 65 points: 1 student
To the nearest tenth of a point, what is the standard deviation of the exam scores for the students in this sample?
8. A manufacturer of jet engines measures a turbine part to the nearest 0.001 centimeters. A sample of parts has the following data set: 5.001, 5.002, 5.005, 5.000, 5.010, 5.009, 5.003, 5.002, 5.001, 5.000. What is the standard deviation for this sample?
9. Two companies pay their employees the same average salary of $42,000 per year. The salary data in Ace Corp. has a standard deviation of $10,000, whereas Magna Company salary data has a standard deviation of $30,000. What, if anything, does this mean?
10. In which of the following situations would having a small standard deviation be most important?
(A) determining the variation in the wealth of retired people
(B) measuring the variation in circuitry components when manufacturing computer chips
(C) comparing the population of cities in different areas of the country
(D) comparing the amount of time it takes to complete education courses on the Internet
(E) measuring the variation in the production of different varieties of apple trees
11. Everyone at a company is given a year-end bonus of $2,000. How will this affect the standard deviation of the annual salaries in the company that year?
12. Calculate the sample variance and the standard deviation for the following measurements of weights of apples: 7 oz, 6 oz, 5 oz, 6 oz, 9 oz. Express your answers in the proper units of measurement and round to the nearest tenth.
13. Calculate the sample variance and the standard deviation for the following measurements of assembly time required to build an MP3 player: 15 min, 16 min, 18 min, 10 min, 9 min. Express your answers in the proper units of measurement and round to the nearest whole number.
14. Which of the following data sets has the same standard deviation as the data set with the numbers 1, 2, 3, 4, 5? (Do this problem without any calculations!)
(A) Data Set 1: 6, 7, 8, 9, 10
(B) Data Set 2: –2, –1, 0, 1, 2
(C) Data Set 3: 0.1, 0.2, 0.3, 0.4, 0.5
(D) Choices (A) and (B)
(E) None of the data sets gives the same standard deviation as the data set 1, 2, 3, 4, 5.
1. (Ans) how concentrated the data is around the mean
A standard deviation measures the amount of variability among the numbers in a data set. It calculates the typical distance of a data point from the mean of the data. If the standard deviation is relatively large, it means the data is quite spread out away from the mean. If the standard deviation is relatively small, it means the data is concentrated near the mean.
2. ( Ans) approximately 68%
According to the empirical rule, the bell-shaped curve of a normal distribution will have 68% of the data points within one standard deviation of the mean.
3. (Ans) E. Choice (A) or (C) (standard deviation or variance)
The standard deviation is a way of measuring the typical distance that data is from the mean and is in the same units as the original data. The variance is a way of measuring the typical squared distance from the mean and isn’t in the same units as the original data. Both the standard deviation and variance measure variation in the data, but the standard deviation is easier to interpret.
4. (Ans) E. Choices (A) and (C) (margin of error; standard deviation)
The standard deviation measures the typical distance from the data to the mean (using all the data to calculate). Outliers are far from the mean, so the more outliers there are, the higher the standard deviation will be. You calculate the margin of error by using the sample standard deviation so it’s also sensitive to outliers. The interquartile range is the range of the middle 50% of the data, so outliers won’t be included, making it less sensitive to outliers than the standard deviation or margin of error
5. (Ans) 5 years
The formula for the sample standard deviation of a data set is
s=√[∑(x− ̄x)²/ n−1 ]where x is a single value, ̄x is the mean of all the values, represents the sum of the squared differences from the mean, and n is the sample size.
First, find the mean of the data set by adding together the data points and then dividing by the sample size (in this case, n = 10):
̄x =(0+1+2+4+8+3+10+17+2+7) /10
=54 /10
=5.4
Then, subtract the mean from each number in the data set and square the differences, (x – ̄x)²: (0 – 5.4)² = (–5.4)²= 29.16
(1 – 5.4)²= (–4.4)² = 19.36
(2 – 5.4)² = (–3.4)² = 11.56
(4 – 5.4)² = (–1.4)² = 1.96
(8 – 5.4)² = (2.6)² = 6.76
(3 – 5.4)² = (–2.4)² = 5.76
(10 – 5.4)²= (4.6)²= 21.16
(17 – 5.4)² = (11.6)²= 134.56
(2 – 5.4)² = (–3.4)²= 11.56
(7 – 5.4)²= (1.6)² = 2.56
Next, add up the results from the squared differences: 29.16 + 19.36 + 11.56 + 1.96 + 6.76 + 5.76 + 21.16 + 134.56 + 11.56 + 2.56 = 244.4 Finally, plug the numbers into the formula for the sample standard deviation:
s=
√{∑(x− ̄x)2 /n−1} =√(244.4/ 10−1) =√27.156 =5.21 The question asks for the nearest year, so round to 5 years.
6. (Ans) 8 years
The formula for the sample standard deviation of a data set is
s=√{∑(x− ̄x)²/ n−1} where x is a single value, ̄x is the mean of all the values, represents the sum of the squared differences from the mean, and n is the sample size
First, find the mean of the data set by adding together the data points and then
dividing by the sample size (in this case, n = 12):
̄x =(12+10+16+22+24+18+30+32+19+20+35+26)/ 12
=264 /12
=22
Then, subtract the mean from each number in the data set and square the differences, (x – ̄x)2:
(12 – 22)² = (–10)² = 100
(10 – 22)²= (–12)² = 144
(16 – 22)² = (–6)² = 36
(22 – 22)² = (0)² = 0
(24 – 22)² = (2)² = 4
(18 – 22)²= (4)² = 16
(30 – 22)² = (8)²= 64
(32 – 22)² = (10)² = 100
(19 – 22)²= (–3)² = 9
(20 – 22)² = (–2)² = 4
(35 – 22)² = (13)² = 169
(26 – 22)² = (4)² = 16
Next, add up the results from the squared differences: 100 + 144 + 36 + 0 + 4 + 16 + 64 + 100 + 9 + 4 + 169 + 16 = 662 Finally, plug the numbers into the formula for the sample standard deviation:
s=√{∑(x− ̄x)²/ n−1} =√(662 /12−1) =√60.1818 =7.76 The question asks for the nearest year, so round to 8 years.
7. (Ans) 8.7 points
The formula for the sample standard deviation of a data set is
s=√[∑(x− ̄x)²/ n−1 ]where x is a single value, ̄x is the mean of all the values, represents the sum of the squared differences from the mean, and n is the sample size.
First, find the mean of the data set. Although you don’t have a list of all the individual values, you do know the test score for each student in the sample. For example, you know that three students scored 92 points, so if you listed every student’s score individually, you’d see 92 three times, or (92)(3). To find the mean this way, multiply each exam score by the number of students who received that score, add the products together, and then divide by the number of students in the sample (n = 20):
(98)(2) = 196
(95)(1) = 95
(92)(3) = 276
(88)(4) = 352
(87)(2) = 174
(85)(2) = 170
(81)(1) = 81
(78)(2) = 156
(73)(1) = 73
(72)(1) = 72
(65)(1) = 65
̄x =196+95+276+352+174+170+81+156+73+72+65 /20
=1,710/ 20
=85.5
Next, subtract the mean from each different exam score in the data set and square the differences, (x – ̄x)². Note: There are 11 different exam scores here — 98, 95, 92, 88, 87, 85, 81, 78, 73, 72, and 65 — but 20 students. First, work with the 11 exam scores.
(98 – 85.5)2 = (12.5)2 = 156.25
(95 – 85.5)2 = (9.5)2 = 90.25
(92 – 85.5)2 = (6.5)2 = 42.25
(88 – 85.5)2 = (2.5)2 = 6.25
(87 – 85.5)2 = (1.5)2 = 2.25
(85 – 85.5)2 = (–0.5)2 = 0.25
(81 – 85.5)2 = (–4.5)2 = 20.25
(78 – 85.5)2 = (–7.5)2 = 56.25
(73 – 85.5)2 = (–12.5)2 = 156.25
(72 – 85.5)2 = (–13.5)2 = 182.25
(65 – 85.5)2 = (–20.5)2 = 420.25
Now, multiply each value by the number of students who got that score: (156.25)(2) = 312.5
(90.25)(1) = 90.25
(42.25)(3) = 126.75
(6.25)(4) = 25
(2.25)(2) = 4.5
(0.25)(2) = 0.5
(20.25)(1) = 20.25
(56.25)(2) = 112.5
(156.25)(1) = 156.25
(182.25)(1) = 182.25
(420.25)(1) = 420.25
Then, add up those results: 312.5 + 90.25 + 126.75 + 25 + 4.5 + 0.5 + 20.25 + 112.5 + 156.25 + 182.25 + 420.25 = 1,451 Finally, plug the numbers into the formula for the sample standard deviation
s=√{(x-x¯)/n-1}=√(1451/20-1 )=√76.37=8.74
The question asks for the nearest tenth of a point, so round to 8.7.
8. (Ans) 0.0036 cm
The formula for the sample standard deviation of a data set is
s=√[∑(x− ̄x)²/ n−1 ]
where x is a single value, ̄x is the mean of all the values, represents the sum of the squared differences from the mean, and n is the sample size.
First, find the mean of the data set by adding together the data points and then dividing by the sample size (in this case, n = 10):
̄x =(5.001+5.002+5.005+5.010+5.009+5.003+5.002+5.001+5.000)/ 10
=50.033/ 10
=5.0033
Then, subtract the mean from each number in the data set and square the differences, (x – ̄x)²:
(5.001 – 5.0033)² = (–0.0023)² = 0.00000529
(5.002 – 5.0033)² = (–0.0013)² = 0.00000169
(5.005 – 5.0033)² = (0.0017)² = 0.00000289
(5.000 – 5.0033)² = (–0.0033)² = 0.00001089
(5.010 – 5.0033)² = (0.0067)² = 0.00004489
(5.009 – 5.0033)² = (0.0057)² = 0.00003249
(5.003 – 5.0033)² = (–0.0003)² = 0.00000009
(5.002 – 5.0033)² = (–0.0013)² = 0.00000169
(5.001 – 5.0033)² = (–0.0023)² = 0.00000529
(5.000 – 5.0033)² = (–0.0033)² = 0.00001089
Next, add up the results from the squared differences: 0.00000529 + 0.00000169 + 0.00000289 + 0.00001089 + 0.00004489 + 0.00003249 + 0.00000009 + 0.00000169 + 0.00000529 + 0.00001089 = 0.0001161 Finally, plug the numbers into the formula for the sample standard deviation:
s=√{∑(x− ̄x)²/n−1} =√(0.0001161 /10−1 )=√0.0000129 =0.0036 The sample standard deviation for the jet engine turbine part is 0.0036 centimeters.
9. (Ans) There is more variation in salaries in Magna Company than in Ace Corp.
The larger standard deviation in Magna Company shows a greater variation of salaries in both directions from the mean than Ace Corp. The standard deviation measures on average how spread out the data is (for example, the high and low salaries at each company).
10. (Ans) B. measuring the variation in circuitry components when manufacturing computer chips
The quality of the vast majority of manufacturing processes depends on reducing variation to as little as possible. If a manufacturing process has a large standard deviation, it indicates a lack of predictability in the quality and usefulness of the end product.
11. (Ans) There will be no change in the standard deviation.
All the data points will shift up $2,000, and as a result, the mean will also increase by $2,000. But each individual salary’s distance (or deviation) from the mean will be the same, so the standard deviation will stay the same.
12. (Ans) The sample variance is 2.3 ounces². The standard deviation is 1.5 ounces.
You find the sample variance with the following formula: s² = ∑(x− ̄x)²/n−1 where x is a single value, ̄x is the mean of all the values, represents the sum of the squared difference scores, and n is the sample size. First, find the mean by adding together the data points and dividing by the sample size (in this case, n = 5):
̄x =7+6+5+6+9 5
=33 5
=6.6 Then, subtract the mean from each data point and square the differences, (x− ̄x)²:
(7 – 6.6)² = (0.4)² = 0.16
(6 – 6.6)² = (–0.6)² = 0.36
(5 – 6.6)²= (–1.6)² = 2.56
(6 – 6.6)² = (–0.6)² = 0.36
(9 – 6.6)² = (2.4)² = 5.76
Next, plug the numbers into the formula for the sample variance:
The sample variance is 2.3 ounces². But these units don’t make sense because there’s no such thing as “square ounces.” However, the standard deviation is the square root of the variance, so it can then be expressed in the original units: s = 1.5 ounces (rounded). For this reason, standard deviation is preferred over the variance when it comes to measuring and interpreting variability in a data set.
13. (Ans) The sample variance is 15 minutes². The standard deviation is 4 minutes.
The formula for the sample standard deviation of a data set is
s=√[∑(x− ̄x)²/ n−1 ]
where x is a single value, ̄x is the mean of all the values, represents the sum of the squared differences from the mean, and n is the sample size.
First, find the mean by adding together the data points and dividing by the sample size (in this case, n = 5):
̄x =15+16+18+10+9/ 5
=68/ 5
=13.6 Then, subtract the mean from each data point and square the differences, (x− ̄x)2:
(15 – 13.6)2 = (1.4)2 = 1.96
(16 – 13.6)2 = (2.4)2 = 5.76
(18 – 13.6)2 = (4.4)2 = 19.36
(10 – 13.6)2 = (–3.6)2 = 12.96
(9 – 13.6)2 = (–4.6)2 = 21.16
Next, plug the numbers into the formula for the sample variance:
s² = ∑(x− ̄x)²/n−1
=1.96+5.76+19.36+12.96+21.16 /5−1
=61.2/ 4
=15.3
The sample variance is 15.3 minutes². But these units don’t make sense because there’s no such thing as “square minutes.” However, the standard deviation is the square root of the variance, so it can then be expressed in the original units: s = 3.91 minutes (rounded up to 4). For this reason, standard deviation is preferred over the variance when it comes to measuring and interpreting variability in a data set.
14. (Ans) D. Choices (A) and (B) (Data Set 1; Data Set 2)
The original data set contains the numbers 1, 2, 3, 4, 5. Data Set 1 just shifts those numbers up by five units to get 6, 7, 8, 9, 10. Standard deviation represents typical (or average) distance from the mean, and although the mean in Data Set 1 changes from 3 to 8, the distances from each point to that new mean stay the same as they were for the original data set, so the average distance from the mean is the same. Data Set 2 contains the numbers –2, –1, 0, 1, 2. These numbers shift the original data set’s values down by three units. For example, 1 – 3 = –2, 2 – 3 = –1, and so forth. Therefore, the standard deviation doesn’t change from the original data set. Data Set 3 divides all the numbers in the original data set by 10, making them closer to the mean, on average, than the original data set. Therefore, the standard deviation is smaller.
Reference
Statistics: 1,001 Practice Problems For Dummies.
Revised by
- Saifun Nahar Smriti on 16 August, 2020. (This article needs further improvement.)
The post Measures of Dispersion appeared first on Plantlet.
]]>The post Organisation and Presentation of Data appeared first on Plantlet.
]]>There are two main methods of presenting data of a variable character or a variable.
A) Tabulation/Tabular Presentation
B) Drawing/Graphical Presentation
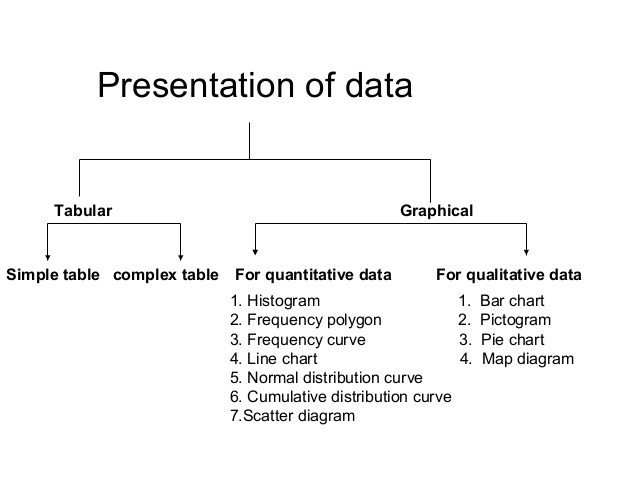
Tabulation
Tabulation is a device for presenting data from a mass of statistical data. Preparation of frequency distribution table is the first requirement for that. Tables are often simple or complex depending upon the measurement of a single set of things or multiple sets of things.
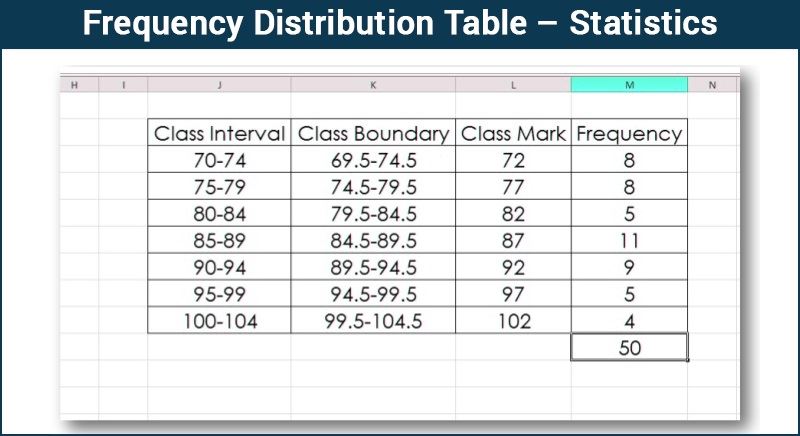
Frequency Distribution
The distribution of the overall number of observations among the various categories is termed as frequency distribution.
Frequency Distribution is a very important step in statistical analysis. It groups a sizable amount of series or observations of the master table and presents the data very concisely, giving all information at a look.
It records how frequently a characteristic or an occurrence occurs in persons of the same group. Data are often recorded within the sort of frequency table.
In short, collecting and summarizing a great amount of data is called frequency distribution.
Rules for Making Frequency Distribution Table
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
- The class or group interval between the groups should not be excessively broad or narrow. Too large a group will omit the details and too small will defeat the purpose of making the data concise.
- The number of groups or classes should not be too many or very few but ordinarily between 6 and 16 depending on the details necessary and the size of the sample.
- The class interval should be the same.
- The headings must be clear for instance “height” in inches or in centimeters, “age” in years or months. If the data are expressed as rates mention percent or per thousand.
- The rates and proportions, if given the actual number in the group must also be noted.
- Groups should be tabulated in ascending or descending order.
- If certain data are omitted or excluded deliberately, the reasons for doing that should be given.
Types of Tabulation
- Simple Tabulation
- Complex Tabulation
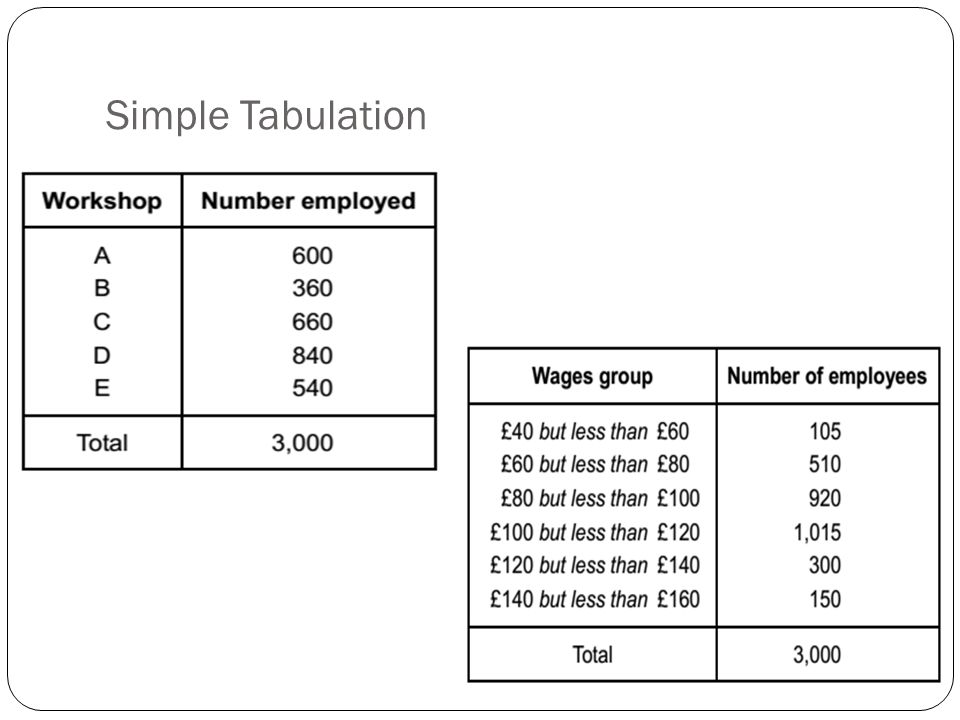
1. Simple Tabulation
Simple Tabulation is when the information/data are tabulated to one characteristic. For example, the survey determined the frequency or number of employees of a firm owning different brands of mobile phones.
2. Complex tabulation
When the data are tabulated consistently with many characteristics, it is said to be a complex tabulation.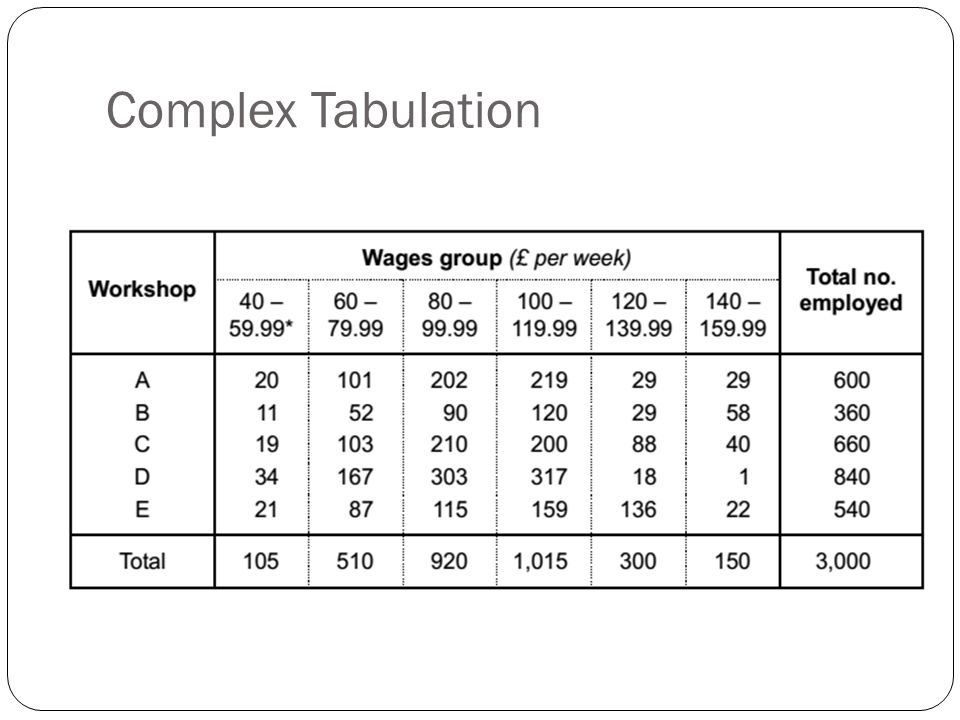
Grafical Distribution
According to the type of data, graphical distribution or drawing is categorized as follows:
A) Graphs for quantitative data
1) Histogram
A histogram is a graphical display of data using bars of various heights. In a histogram, each bar groups numbers into ranges. Taller bars show that more data falls in this range. A histogram displays the form/shape and spread of continuous sample data.
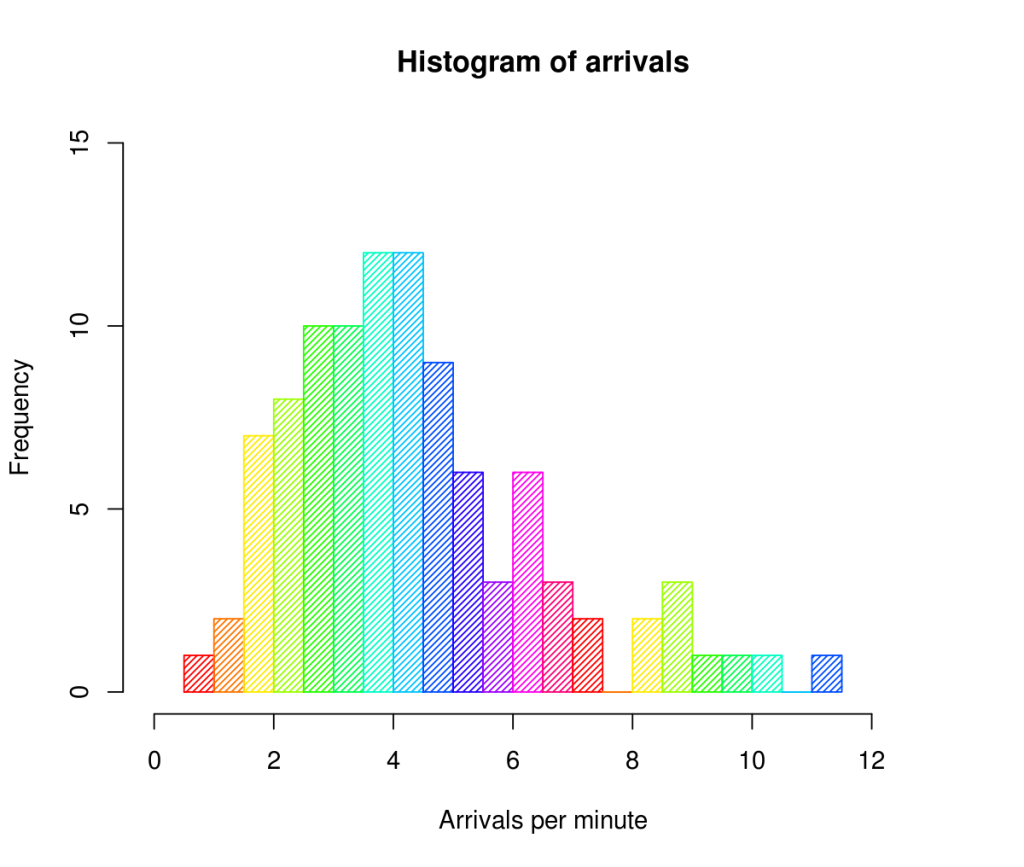
2) Frequency Polygon
A frequency polygon is a graph constructed by using lines to join the midpoints of every interval or bin. The heights of the points depict the frequencies. A frequency polygon is usually created from the histogram or by calculating the midpoints of the bins from the frequency distribution table.
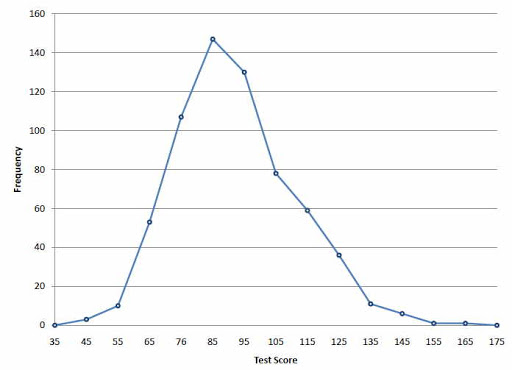
3) Frequency Curve
A frequency curve is a smooth curve for which the entire area is taken to be unity. It’s a limiting sort of a histogram or frequency polygon. The frequency curve for distribution is obtained by drawing a smooth and freehand/blank check curve through the mid-points of the upper sides of the rectangles forming the histogram.
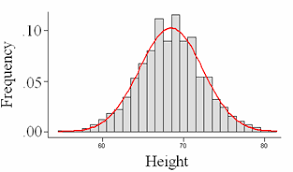
4) Line Chart
A line chart is a graphical representation of an asset’s historical price action that connects a series of data points with a continual line. This is often the foremost basic type of chart used in finance and typically only depicts a security’s closing prices over time.
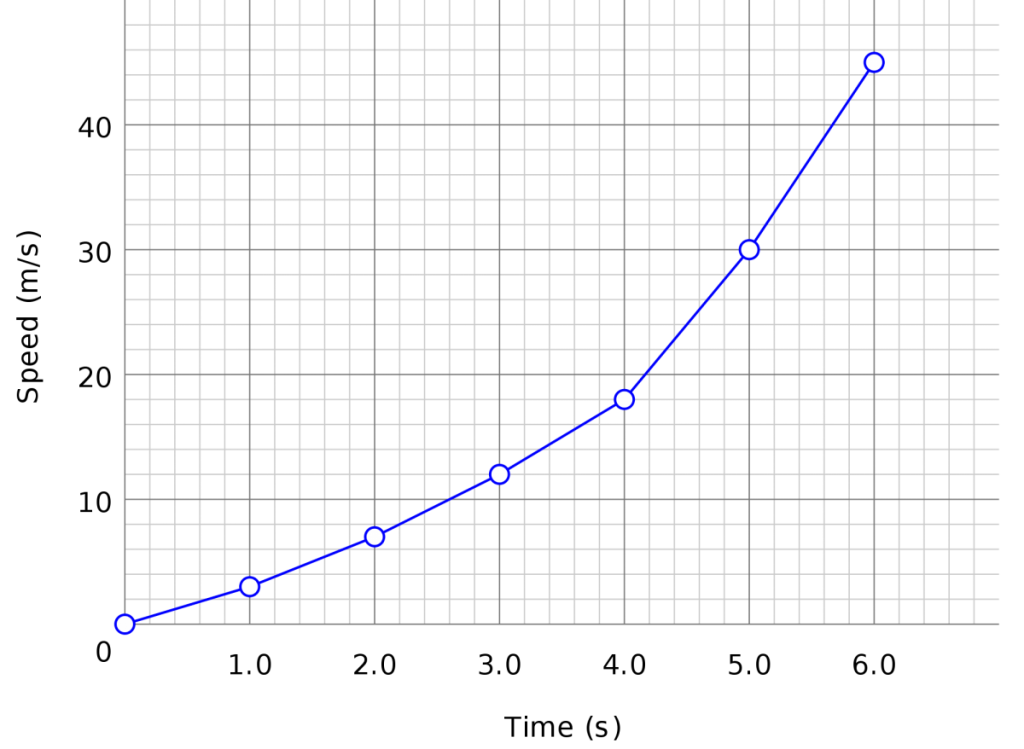
5) Normal Distribution Curve
A normal distribution is a type of continuous probability distribution for a real-valued random variable. A normal distribution is usually informally called a bell curve.
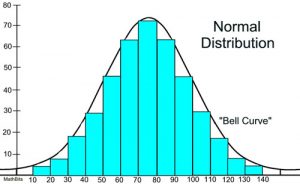
6) Cumulative Distribution Curve
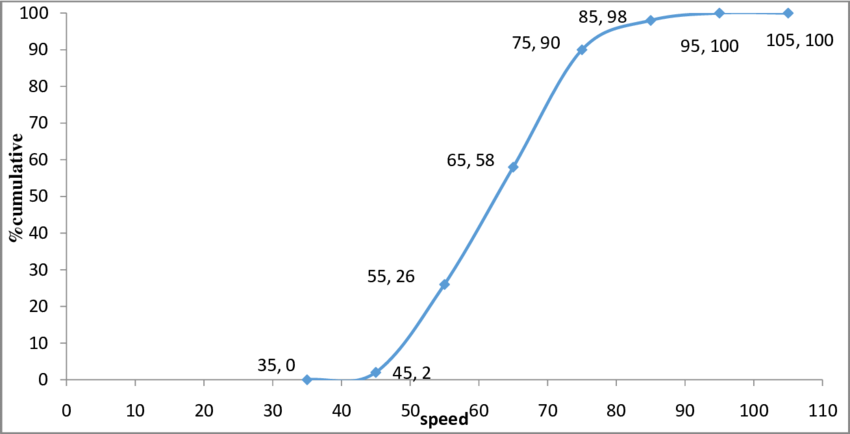
In statistics, the cumulative distribution function of a real-valued random variable, or just distribution function of, evaluated at, is the probability that will take a value less than or adequate to.
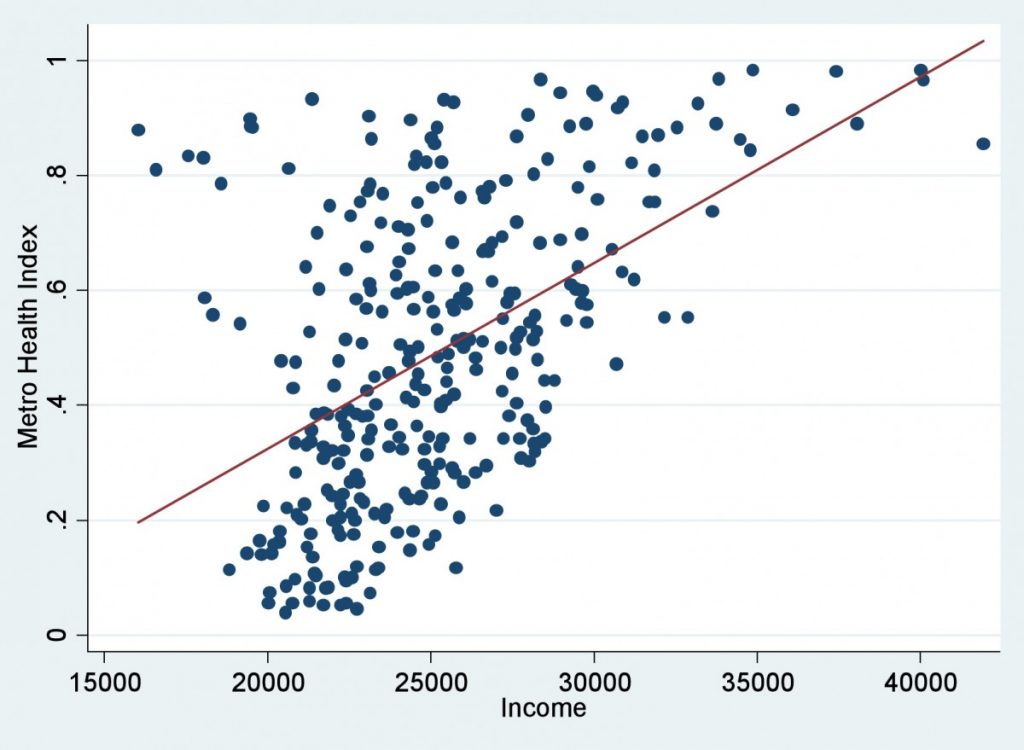
7) Scatter Diagram
A graph during which the values of two variables are plotted along two axis, the pattern of the resulting points revealing any correlation present.
B) Diagrams for qualitative data
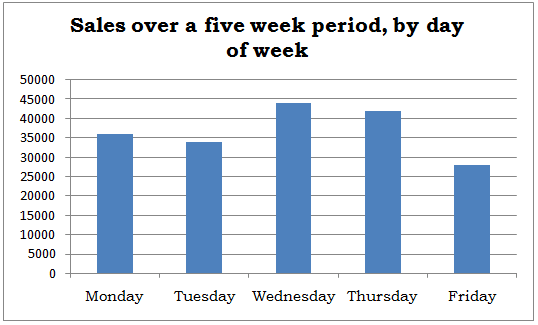
1) Bar Chart
A bar chart or bar graph is a chart or graph that presents categorical data with rectangular bars with heights or lengths proportional to the values that they represent. The bars can be often plotted vertically or horizontally. A vertical bar chart is usually called a column chart.
2) Pictogram
A pictogram is a chart that uses pictures to represent data. Pictograms are set out in the same way as to bar charts, but rather than bars they use columns of pictures to point out the numbers involved.

3) Pie Chart
A pie chart is a sort of graph in which a circle is split into sectors that each represents a proportion of the entire. Pie charts are a useful way to organize data in order to see the size of components relative to the entire and are particularly good at showing percentage or proportional data.
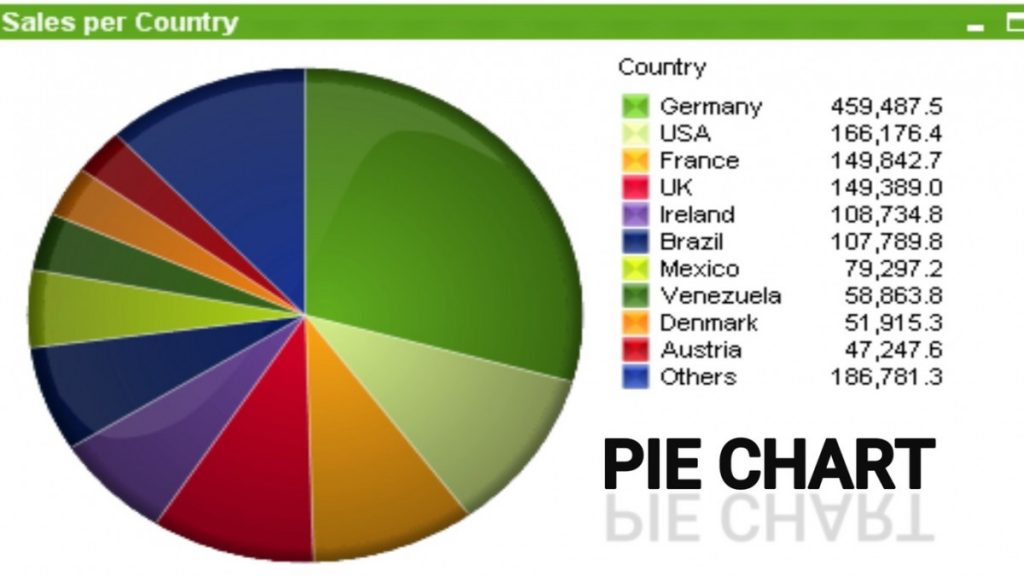
4) Map Diagram
A map diagram is a way of representation of any event distribution by means of diagrams, that are placed on the map inside the structure of territorial division which expresses the summarized value of this event within the bounds of this territorial structure.
Q&A
You Are interested in the percentage of female versus male shoppers at a department store.
Which chart or graph would be appropriate to display the proportion of males versus females among the shoppers?
A)A bar graph
B)A time plot
C)A pie chart
D)Choices (A) and (C)
E)Choices (A),(B) and (C)
Ans: (D)
Gender is a qualitative variable, so both bar graphs and pie charts are appropriate to display the proportion of males versus females among the shoppers. You could use a time plot only if you knew how many males and how many females were in the store at each individual time period.
Ref:Statistics: 1,001 Practice Problems For Dummies
Source:
1. Feature image: https://epthinktank.eu/2015/08/17/eprs-graphic-warehouse-when-a-picture-tells/amp/
2. Methods of Biostatistics- Mahajan
Revised by:
1. Tarek siddiki Taki ( 08.08.2020)
The post Organisation and Presentation of Data appeared first on Plantlet.
]]>The post Measures of Central Value: Mean, Median, Mode & Others appeared first on Plantlet.
]]>There are various methods to measure the central value of an observation. For instance, average, mean, median, mode, etc.
Average
The average value of a characteristic is the one central value around which all other observations are distributed. In any large series, nearly 50% of observations lie above the central value whereas the other 50% lie below the central value. It indicates how the values lie close to the center.
**Average is the measure that indicates the central tendency or concentration of all other observations around the central value.
There are three types of averages or measures of central position or central tendency -mean, median, and mode.
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
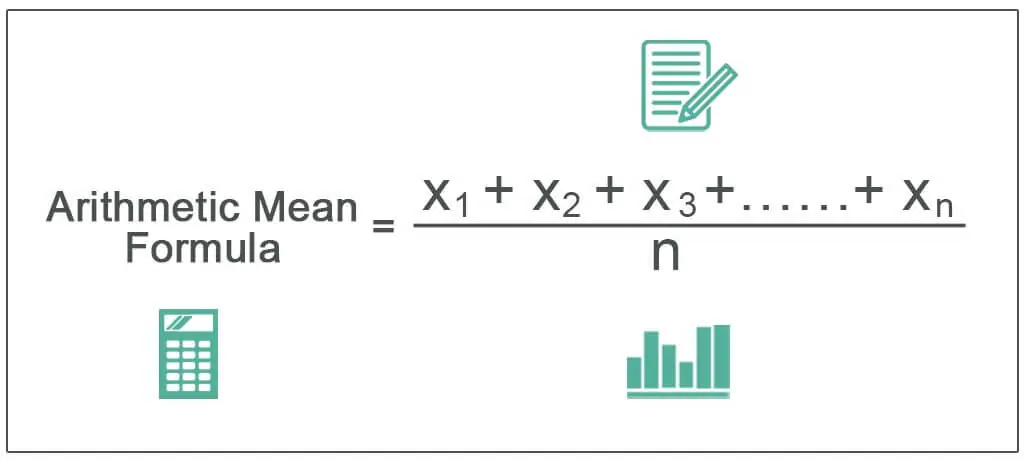
Mean
This is an arithmetic average of a collection of values. It is the sum of observations divided by the number of observations.
Let,the observations are x1,x2,x3,….
Mean=∑x/n (n=number of observations)
Mean in case of continuous series:
| Number of organisms | frequency(f) | midpoint(m) | f×m |
| 5-9 | 3 | 7 | 21 |
| 10-14 | 5 | 12 | 60 |
| 15-19 | 6 | 17 | 102 |
| 20-24 | 4 | 22 | 88 |
| 25-29 | 3 | 27 | 81 |
| ∑f=21 | ∑fm=352 |
x¯=∑fm/∑f=352/21=16.76
Median
When all the observations of a variable one arranged in either ascending or descending order, the middle observation is known as the median.
The median is a locational average & it is that value that divides the series into two equal shares in a series of observations. The median equally divides the number of items of observations.

With an even number of observations
The Median will be the average of two values according to the following formula.
when,n=10
n/2=10/2=5th
(n+2)/2=(10+2)/2=6th, Here median will be the average of 5th & 6th value of the series.
Example:4,6,7,8,8,9,11,12,12,14 Here,5th value=8 & 6th value=9
Now,median=(8+9)/2=17/2=8.5
With odd number of observations
Number of nodules/root:7,6,9,8,9,10,6,7,10
Arranged in ascending order:6,6,7,7,8,9,9,10,10
Median=(n+1)/2=(9+1)/2=5th value=8
Median in case of classified data
|
Time (Sec) Class Interval |
Frequency | Cumulative Frequency |
| 30-35 | 3 | 3 |
| 36-41 | 10 | 13 |
| 42-47 | 18 | 31 |
| 48-53 | 25 | 56 |
| 54-59 | 8 | 64 |
| 60-65 | 6 | 70 |
| ∑n=70 |
Median=L+{(n/2-Fc)/fm}×h=48+{(70/2-31)/25}×6=48.96
L= lower value of the highly frequent class (48-53)
n=number of observations [n=70],[2f=70]
Fc=cumulative value of the previous class of the median class [Fc=31]
fm= frequency of median class
h=class interval[h=6]
Mode
This is the most frequently occurring observation in a series.
Mode is the type of average that refers to the most common or most regularly occurring value in a series of data.
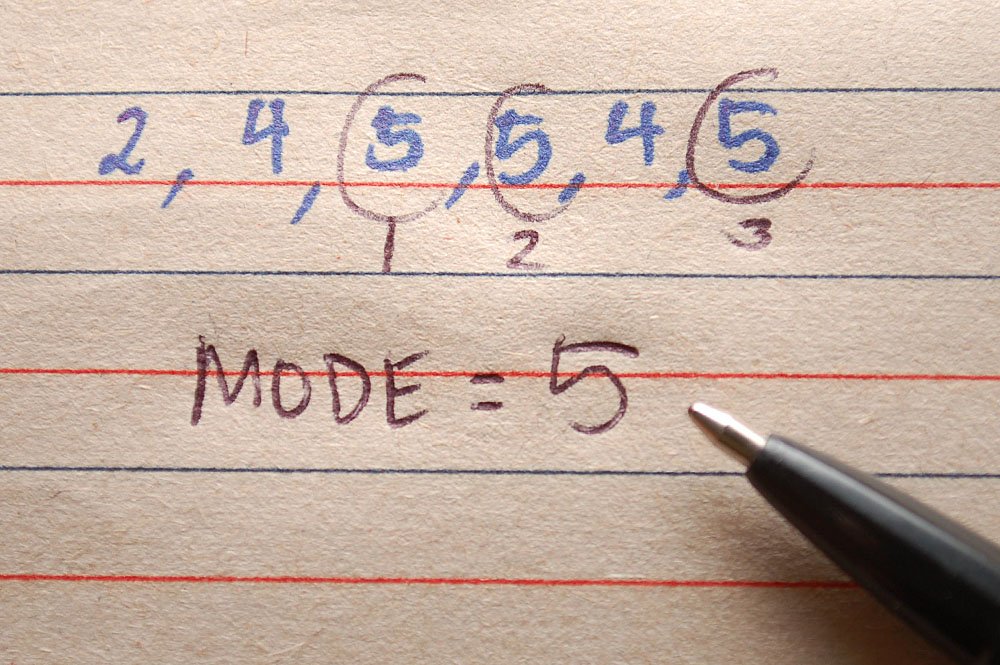
Calculation of mode from classified data
| Class | Frequency |
| 31-40 | 4 |
| 41-50 | 6 |
| 51-60 | 8 |
| 61-70 | 12 |
| 71-80 | 9 |
| 81-90 | 7 |
| 91-100 | 4 |
Mode=L+{f1/(f1+f2)}×h=61+{4/(4+3)}×10=61+0.57×9=66.71
Here,
L=lower value of the modal class=61
f1=frequency of the modal class – frequency of the previous class=12-8=4
f2=frequency of the modal class – frequency of the next class=12-9=3
h=class interval=10
**Out of three measures of central tendency mean is better and utilized more often because it uses all the observations in the data and is further used in the tests of significance
Symmetrical Distribution
Symmetrical distribution is a distribution in which the values of variables occur at regular frequencies, and the mean, median, and mode occur at the same point. Unlike asymmetrical distribution, symmetrical distribution does not skew.
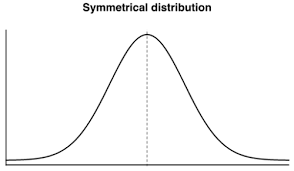
**In short, the distributions in which both sides are the same(mirror image) about the middle ordinate is called symmetrical distribution.
Asymmetrical Distribution
Asymmetrical distribution is a distribution in which the values of variables occur at irregular frequencies and the mean, median, and mode occur at different points. An asymmetric distribution exhibits skewness.

Skewed Distribution
Some distributions are steep on one side and have a long tail on the other side. This characteristic of a distribution is called skewness.
If the tail is on the right side the distribution is said to be skewed right. This type of skewness is called positive skewness.
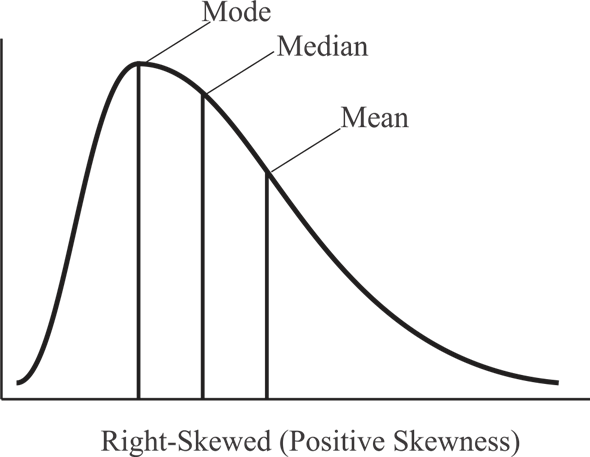
**Biological phenomena are very commonly skewed right.
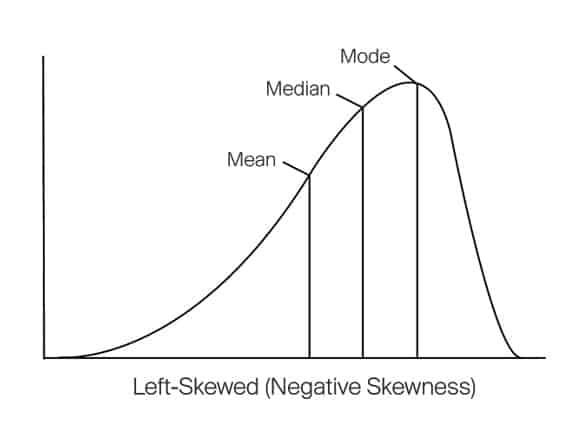
If the tail is on the left side, the distribution is said to be skewed left. This type of skewness is called negative skewness.
**Skewness is a measure of symmetry, or to say more certainly, the lack of symmetry.
Kurtosis
Similar to skewness, kurtosis is a statistical measure that is used to describe the distribution.
Kurtosis is a measure of whether or not the data are heavy-tailed or light-tailed relative to a normal distribution. That is, data sets with high kurtosis tend to own heavy tails or outliers. Data sets with low kurtosis tend to own light tails or lack of outliers.

**Kurtosis=3 depicts the normal distribution
Outlier
In statistics, an outlier is a data point that differs considerably from other observations. An outlier may be due to variability in the measurement or it may suggest experimental error; the latter are generally excluded from the data set. An outlier can cause serious issues in statistical analyses.
Q&A
1. Which of the following data sets has a median of 3?
(A) 3, 3, 3, 3, 3
(B) 2, 5, 3, 1, 1
(C) 1, 2, 3, 4, 5
(D) 1, 2, 4, 4, 4
(E) Choices (A) and (C)
2. To the nearest tenth, what is the mean of the following data set? 14, 14, 15, 16, 28, 28, 32, 35, 37, 38
3. To the nearest tenth, what is the mean of the following data set? 15, 25, 35, 45, 50, 60, 70, 72, 100
4. To the nearest tenth, what is the mean of the following data set? 0.8, 1.8, 2.3, 4.5, 4.8, 16.1, 22.3
5. To the nearest thousandth, what is the mean of the following data set? 0.003, 0.045, 0.58, 0.687, 1.25, 10.38, 11.252, 12.001
6. To the nearest tenth, what is the median of the following data set? 6, 12, 22, 18, 16, 4, 20, 5, 15
7. To the nearest tenth, what is the median of the following data set? 18, 21, 17, 18, 16, 15.5, 12, 17, 10, 21, 17
8. To the nearest tenth, what is the median of the following data set? 14, 2, 21, 7, 30, 10, 1, 15, 6, 8
9. To the nearest hundredth, what is the median of the following data set? 25.2, 0.25, 8.2, 1.22, 0.001, 0.1, 6.85, 13.2
10. Compare the mean and median of a data set that has a distribution that is skewed right.
11. Compare the mean and median of a data set that has a distribution that is skewed left.
12. Compare the mean and the median of a data set that has a symmetrical distribution.
13. Which measure of center is most resistant to (or least affected by) outliers?
1. Ans) E. Choices (A) and (C) (3, 3, 3, 3, 3; 1, 2, 3, 4, 5)
To find the median, put the data in order from lowest to highest, and find the value in the middle. It doesn’t matter how many times a number is repeated. In this case, the data sets 3, 3, 3, 3, 3 and 1, 2, 3, 4, 5 each have a median of 3.
2. Ans) 25.7
Use the formula,
¯x=∑x/n
where ̄x is the mean, ∑ represents the sum of the data values, and n is the number of values in the data set. In this case, x = 14 + 14 + 15 + 16 + 28 + 28 + 32 + 35 + 37 + 38 = 257, and n = 10. So the mean is 257 10 =25.
3. Ans) 52.4
Use the formula for calculating the mean
¯x=∑x/n
where ̄x is the mean, ∑ represents the sum of the data values, and n is the number of values in the data set. In this case, x = 15 + 25 + 35 + 45 + 50 + 60 + 70 + 72 + 100 = 472, and n = 9. So the mean is 472 9 =52.4444
The question asks for the nearest tenth, so you round to 52.4.
4. Ans) 7.5
Use the formula for calculating the mean
¯x=∑x/n
where ̄x is the mean, ∑ represents the sum of the data values, and n is the number of values in the data set. In this case, x = 0.8 + 1.8 + 2.3 + 4.5 + 4.8 + 16.1 + 22.3 = 52.6, and n = 7. So the mean is 52.6 7 =7.5143
The question asks for the nearest tenth, so you round to 7.5.
5. Ans) 4.525
Use the formula for calculating the mean
¯x=∑x/n
where ̄x is the mean, ∑ represents the sum of the data values, and n is the number of values in the data set. In this case, x = 0.003 + 0.045 + 0.58 + 0.687 + 1.25 + 10.38 + 11.252 + 12.001 = 36.198, and n = 8. So the mean is 36.198 8 =4.52475
The question asks for the nearest thousandth, so you round to 4.525.
6. Ans) 15.0
To find the median, put the numbers in order from smallest to largest: 4, 5, 6, 12, 15, 16, 18, 20, 22 Because this data set has an odd number of values (nine), the median is simply the middle number in the data set: 15.
7. Ans) 17.0
To find the median, put the numbers in order from smallest to largest: 10, 12, 15.5, 16, 17, 17, 17, 18, 18, 21, 21 Because this data set has an odd number of values (11), the median is simply the middle number in the data set: 17.
8. Ans) 9.0
To find the median, put the numbers in order from smallest to largest: 1, 2, 6, 7, 8, 10, 14, 15, 21, 30 Because this data set has an even number of values (ten), the median is the average of the two middle numbers: 8+10/2 =9.0
9. Ans) 4.04
To find the median, put the numbers in order from smallest to largest. 0.001, 0.1, 0.25, 1.22, 6.85, 8.2, 13.2, 25.2 Because this data set has an even number of values (eight), the median is the average of the two middle numbers: 1.22+6.85/2 =4.035 The question asks for the nearest hundredth, so round to 4.04.
10. Ans) The mean will have a higher value than the median.
A data set distribution that is skewed right is asymmetrical and has a large number of values at the lower end and few numbers at the high end. In this case, the median, which is the middle number when you sort the data from smallest to largest, lies in the lower range of values (where most of the numbers are). However, because the mean finds the average of all the high and low values, the few outlying data points on the high end cause the mean to increase, making it higher than the median.
11. Ans) The mean will have a lower value than the median.
A data set distribution that is skewed left is asymmetrical and has a large number of values at the high end and few numbers at the low end. In this case, the median, which is the middle number when you sort the data from smallest to largest, lies in the upper range of values (where most of the numbers are). However, because the mean finds the average of all the high and low values, the few outlying data points on the low end cause the mean to decrease, making it lower than the median.
12. Ans) The mean and median will be fairly close together.
When a data set has a symmetrical distribution, the mean and the median are close together because the middle value in the data set, when ordered smallest to largest, resembles the balancing point in the data, which occurs at the average.
13. Ans) median
The median is the middle value of the data points when ordered from smallest to largest. When the data is ordered, it no longer takes into account the values of any of the other data points. This makes it resistant to being influenced by outliers. (In other words, outliers don’t really affect the median.) In contrast, the mean takes every specific data value into account. If the data points contain some outliers that are extreme values to one side, the mean will be pulled toward those outliers.
Reference
Statistics: 1,001 Practice Problems For Dummies
The post Measures of Central Value: Mean, Median, Mode & Others appeared first on Plantlet.
]]>The post Random Sampling appeared first on Plantlet.
]]>Sampling
Measuring a small portion of something and then making a general statement about the whole thing is known as sampling.
- Sampling is a process of selecting a number of units for a study in such a way that the units represent the larger group from which they are selected.
Function
Since it is generally impossible to study an entire population (e.g. many individuals in a country, all college students, every geographic area etc.) researchers typically rely on sampling to acquire a section of the population to perform an experiment or observational study.
It is important that the group selected be representative of the population and not biased in a systematic manner.
For example, a group comprised of wealthiest individuals population in a given area probably would not accurately reflect the opinion of the entire population in that area.
Best safe and secure cloud storage with password protection
Get Envato Elements, Prime Video, Hotstar and Netflix For Free
Best Money Earning Website 100$ Day
#1 Top ranking article submission website
Types of Sampling
A. Probability sampling:
A method of sampling that uses random selection so that all units/cases in the population have an equal probability of being chosen is known as probability or random sampling.
Advantages:
1. Easy to conduct.
2. High probability of achieving a representative sample.
3. Meets assumptions ofmany statistical procedure.
Disadvantages:
1. Identification of all members of the population can be difficult.
2. Contacting all members of the sample can be difficult.
B. Non-probability sampling:
Sampling that does not involve random selection and methods are not based on the10rationale of probability theory is non-probability or non-random sampling.
Simple Random Sampling
Simple random sampling is a probability sampling method.
Definition : A Simple Random Sample (SRS) consists of n individuals from the population chosen such a way that every individual has the equal chance to be selected.
Advantage:
1. Simple to conduct.
2. Each unit has an equal chance of being selected.
Disadvantage :
1. Complete list of individuals in the universe is required.
Systemic (Random) Sampling
There is a gap or interval between each between each selected species of the sample.
Selection of units is based on sample interval k starting from a determined point where k= N/n.
Steps:
1. Number the units on your frame from 1 to N, and the population are arranged in the same way.
2. First sample drawn between 1 and K randomly. (Determine present/ random start.)
3. Afterwards, every k th must be drawn, untill the total sample has been drawn.
Stratified Random Sampling
A stratified random sample is obtained by dividing the Population elements into non-overlapping groups, called strata and then selecting a random sample directly and independently from each stratum.
A stratified SRS is a special case of stratified sampling that uses SRS for selecting units from each stratum.
Cluster Sampling
Cluster Sampling is defined as a sampling technique in which the elements of the population is divided in existing groups (cluster).
Then a sample from the cluster is selected randomly from the population.
sub-types:
- Single stage cluster Sampling.
- Double Stage cluster Samplimg.
- Multiple Stage cluster Sampling.
The post Random Sampling appeared first on Plantlet.
]]>